● 프로젝트
-프로젝트 개요:
본 프로젝트에서는 머신러닝/딥러닝을 활용하여 제주도의 퇴근 시간대에 탑승하는 버스 승객 수를 예측
프로젝트는 파이썬을 사용하여 회귀분석을 수행하고, 훈련 데이터와 관련된 내용을 활용하여 예측 모델을 구축
-활용 장비 및 재료:
프로젝트는 Python, pandas, scikit-learn, tensorflow 등의 개발 환경과 라이브러리를 활용
데이터 전처리, 모델 선정, 최적의 모델 및 파라미터 탐색, 분석 및 예측을 위해 이러한 도구 및 자원들을 사용
-프로젝트 구조:
데이터 전처리: 사용할 데이터를 수집하고, 누락된 값이나 이상치를 처리하여 데이터를 정리
모델 선정: 회귀분석에 적합한 모델을 선택하고, 이를 구현
최적의 모델/파라미터 탐색: 다양한 모델과 파라미터를 실험하여 최적의 조합을 탐색
분석 및 예측: 최종 모델을 사용, 퇴근 시간대의 버스 탑승 승객 수를 예측 및 이를 분석
-기대 효과:
본 연구를 통해 효율적인 제주도 버스 배차 시간 및 정류장을 관리할 수 있는 정보를 얻을 수 있으며
이를 통해 교통 혼잡을 완화하고 승객들의 이동을 효율적으로 지원할 수 있다
● 프로젝트 계획
| 구분 | 기간 | 활동 | 비고 |
| 사전 기획 | ▶ 5/9(화) ~ 5/10(수) | ▶ 프로젝트 기획 ▶ ppt 작성 |
▶ csv 파일을 보고 분석 모델 예측 |
| 데이터 전처리 | ▶ 5/9(화) ~ 5/19(금) | ▶ python 코딩 및 데이터 정제 | |
| 모델링 | ▶ 5/11(목) ~ 5/19(금) | ▶boost계열 regressor 회귀분석 | ▶voting 최적 모델 선정 |
| 알고리즘 구축 및 파라미터 설정 | ▶ 5/11(목) ~ 5/19(금) | ▶ 최적의 알고리즘 구축 ▶최적의 파라미터 설정 |
▶ optuna 최적 파라미터 탐색 |
| 총 개발기간 | ▶ 5/9(월) ~ 5/19(금)(총 2주) | ||
●데이터 분석(train_data)
| 컬럼 명 | 설명 |
| id | 데이터 고유 ID(train, test와의 중복 없음) |
| date | 날짜 |
| bus_route_id | 노선 ID |
| in_out | 시내버스, 시외버스 구분 |
| station_code | 해당 승하차 정류소 ID |
| station_name | 해당 승하차 정류소 이름 |
| latitude | 해당 버스 정류장 위도 |
| longitude | 해당 버스 정류장 경도 |
| X~Y_ride | X:00:00부터 X:59:59까지 승차한 인원 수 |
| X~Y_takeoff | X:00:00부터 X:59:59까지 하차한 인원 수 |
| 18~20_ride | 18:00:00부터 19:59:59까지 승차한 인원 수 |

● 이상치 확인
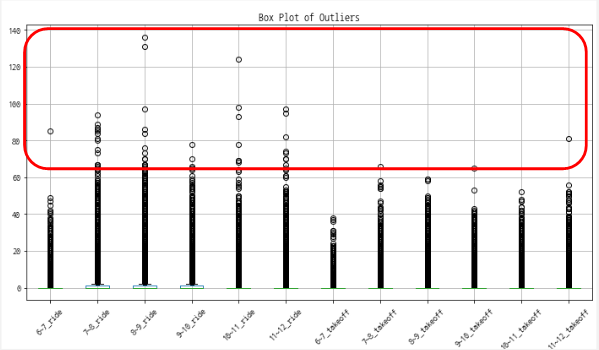

-훈련시킬 train데이터의 이상치 확인
● 시각화

- 시간대별 승하차량 차이를 확인
- 탑승객은 주말보다 평일에 더 많은 것을 확인 -> 날짜별로 구분 + 시간대 별로 구분
● 코드(데이터 전처리)
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from sklearn.preprocessing import RobustScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MaxAbsScaler
from sklearn.preprocessing import PowerTransformer
from sklearn.preprocessing import QuantileTransformer
from sklearn.preprocessing import FunctionTransformer
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressorpath = './'
datasets = pd.read_csv(path + 'train.csv')# 1. x, y Data
x = datasets[['id', 'bus_route_id', 'in_out', 'station_code', 'station_name',
'latitude', 'longitude', '6~7_ride', '7~8_ride', '8~9_ride',
'9~10_ride', '10~11_ride', '11~12_ride', '6~7_takeoff', '7~8_takeoff',
'8~9_takeoff', '9~10_takeoff','10~11_takeoff','11~12_takeoff']].copy()
# ride 카테고리
x['takeon_avg_6~8'] = (x['6~7_ride'] + x['7~8_ride']) / 2
x['takeon_avg_8~10'] = (x['8~9_ride'] + x['9~10_ride']) / 2
x['takeon_avg_10~12'] = (x['10~11_ride'] + x['11~12_ride']) / 2
x['takeon_avg_ride'] = (x['takeon_avg_6~8'] + x['takeon_avg_8~10'] + x['takeon_avg_10~12']) / 3
# takeoff 카테고리
x['takeoff_avg_6~8'] = (x['6~7_takeoff'] + x['7~8_takeoff']) / 2
x['takeoff_avg_8~10'] = (x['8~9_takeoff'] + x['9~10_takeoff']) / 2
x['takeoff_avg_10~12'] = (x['10~11_takeoff'] + x['11~12_takeoff']) / 2
#x['takeon_avg_takeoff'] = (x['takeoff_avg_6~8'] + x['takeoff_avg_8~10'] + x['takeoff_avg_10~12']) / 3
# date 카테코리
x['date'] = pd.to_datetime(datasets['date'])
y = datasets[['18~20_ride']]
x['date'] = pd.to_datetime(x['date'])
x['year'] = x['date'].dt.year
x['month'] = x['date'].dt.month
x['day'] = x['date'].dt.day
x['weekday'] = x['date'].dt.weekday
x = x.drop('date', axis=1)
# 최대값 중앙값 등
# Calculate statistical aggregations
ride_columns = ['6~7_ride', '7~8_ride', '8~9_ride', '9~10_ride', '10~11_ride', '11~12_ride']
takeoff_columns = ['6~7_takeoff', '7~8_takeoff', '8~9_takeoff', '9~10_takeoff', '10~11_takeoff','11~12_takeoff']
# x['takeoff_mean'] = x[takeoff_columns].mean(axis=1)
x['takeoff_median'] = x[takeoff_columns].median(axis=1)
# x['takeoff_std'] = x[takeoff_columns].std(axis=1)
# Calculate maximum and minimum values
x['ride_max'] = x[ride_columns].max(axis=1)
x['ride_min'] = x[ride_columns].min(axis=1)
# Add weekday/weekend feature
x['is_weekend'] = np.where(x['weekday'] < 5, 0, 1)
x['in_out'] = x['in_out'].map({'시내': 0, '시외': 1})
station_name_mapping = {name: i for i, name in enumerate(x['station_name'].unique())}
x['station_name'] = x['station_name'].map(station_name_mapping)
x_encoded = pd.get_dummies(x, columns=['station_name'])
x_encoded = x_encoded.fillna(0)
x = pd.get_dummies(x, columns=['station_name'])
x = x_encoded.fillna(0)import tensorflow as tf
tf.random.set_seed(30) # weight 난수값 조정x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.15, train_size=0.85, random_state=80, shuffle=True
) # 7:3에서 바꿈
print(x)
from sklearn.ensemble import BaggingRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV, KFold
param = {
'n_estimators': [3947],
'depth': [16],
'fold_permutation_block': [237],
'learning_rate': [0.8989964556692867],
'od_pval': [0.6429734179569129],
'l2_leaf_reg': [2.169943087966259],
'random_state': [1417]
}
bagging = BaggingRegressor(
base_estimator=DecisionTreeRegressor(),
max_features=7,
n_estimators=100,
n_jobs=-1,
random_state=62
)
kfold = KFold(n_splits=10, shuffle=True, random_state=42)
model = GridSearchCV(bagging, param, cv=kfold, refit=True, n_jobs=-1)
depth = param['depth'][0]
l2_leaf_reg = param['l2_leaf_reg'][0]
border_count = param['fold_permutation_block'][0]
print(f"depth: {depth}")
print(f"l2_leaf_reg: {l2_leaf_reg}")
print(f"border_count: {border_count}")
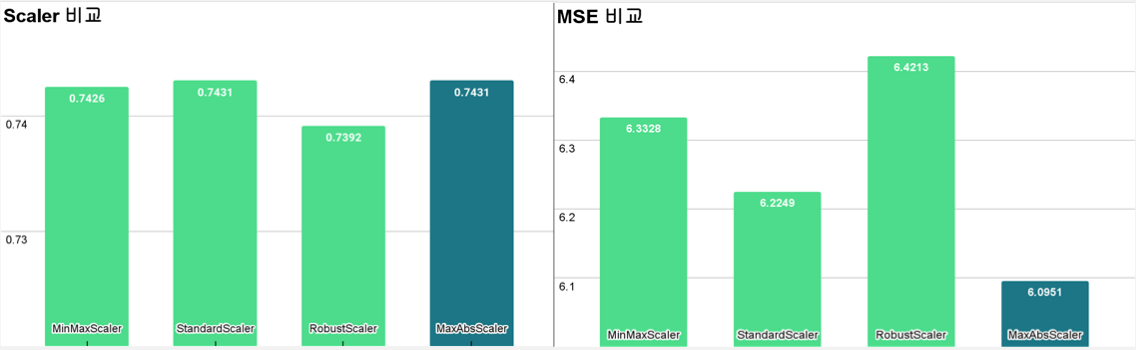
# MaxAbsScaler CatBoostRegressor 정확도 : 0.7431 MSE: 6.636857463485287
scaler = MaxAbsScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# # MinMaxScaler CatBoostRegressor 정확도 : 0.7426 MSE: 6.759033561188409
#scaler = MinMaxScaler()
#x_train = scaler.fit_transform(x_train)
#x_test = scaler.transform(x_test)
# StandardScaler
#scaler = StandardScaler()
#x_train = scaler.fit_transform(x_train)
#x_test = scaler.transform(x_test)
# RobustScaler
# scaler = RobustScaler()
# x_train = scaler.fit_transform(x_train)
# x_test = scaler.transform(x_test)from catboost import CatBoostRegressor#3. 훈련 및 평가예측
xgb = XGBRegressor()
cat = CatBoostRegressor()
lgbm = LGBMRegressor()
regressors = [cat]
for model in regressors:
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
score = r2_score(y_test, y_predict)
class_names = model.__class__.__name__
print('{0} 정확도 : {1: .4}'.format(class_names, score))
# MSE 계산
mse = mean_squared_error(y_test, y_predict)
# MSE 값 출력
print("MSE:", mse)
import matplotlib.pyplot as plt
plt.scatter(y_test, y_predict)
plt.plot(y_test, y_predict, color='Red')
plt.show()
# #4. 시각화 - 산점도 그래프 그리기
plt.figure(figsize=(8, 6))
plt.scatter(y_test.values.ravel(), y_predict)
plt.plot([min(y_test.values.ravel()), max(y_test.values.ravel())], [min(y_test.values.ravel()), max(y_test.values.ravel())], 'k--', lw=2)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Actual vs. Predicted')
plt.show()
# #4. 시각화 - 예측 오차의 분포 그래프 그리기
error = y_predict - y_test.values.ravel()
plt.figure(figsize=(8, 6))
plt.hist(error, bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.title('Prediction Error Distribution')
plt.show()
# #4. 시각화 - 상관계수 히트맵
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale = 1.2)
sns.set(rc = {'figure.figsize':(20, 15)})
sns.heatmap(data=datasets.corr(),
square = True,
annot = True,
cbar = True,
cmap = 'coolwarm'
)
plt.show()
- 코드 리뷰
-필요한 라이브러리를 import
numpy, pandas, keras의 Sequential 모델과 Dense 레이어, sklearn의 MinMaxScaler, train_test_split, KFold, r2_score, mean_squared_error 등을 import, 또한 시각화를 위해 matplotlib의 pyplot을 import
-train.csv 파일을 데이터셋으로 읽어오기
- x와 y 데이터를 설정, x는 'id', 'bus_route_id', 'in_out', 'station_code', 'station_name', 'latitude', 'longitude', '6~7_ride', '7~8_ride', '8~9_ride', '9~10_ride', '10~11_ride', '11~12_ride', '6~7_takeoff', '7~8_takeoff', '8~9_takeoff', '9~10_takeoff', '10~11_takeoff', '11~12_takeoff' 열을 포함
- 'ride' 카테고리에 대한 열들을 활용하여 새로운 특성을 생성, ex) 'takeon_avg_6~8'은 '6~7_ride'와 '7~8_ride'의 평균이고, 'takeon_avg_8~10'은 '8~9_ride'와 '9~10_ride'의 평균
- 'takeoff' 카테고리에 대한 열들을 활용하여 새로운 특성을 생성, ex) 'takeoff_avg_6~8'은 '6~7_takeoff'과 '7~8_takeoff'의 평균이고, 'takeoff_avg_8~10'은 '89_takeoff'와 '9~10_takeoff'의 평균
- 'date' 열을 datetime 형식으로 변환하고, 이를 활용하여 'year', 'month', 'day', 'weekday' 특성을 생성
- 'ride'와 'takeoff' 열들에 대한 통계적 집계를 계산하여 새로운 특성들을 생성, 'takeoff_mean'은 'takeoff' 열들의 평균이고, 'ride_max'는 'ride' 열들의 최댓값
- 주말 여부를 나타내는 'is_weekend' 특성을 생성, 주말인 경우 1, 주중인 경우 0의 값을 갖는다
- 범주형 변수인 'in_out'과 'station_name'을 숫자로 인코딩, 'in_out'은 '시내'를 0, '시외'를 1로 mapping하고, 'station_name'은 고유한 값에 대해 숫자를 할당
- 모든 범주형 변수를 one-hot encoding하여 새로운 열로 추가
- 데이터셋을 훈련 데이터와 테스트 데이터로 나눈다, 훈련 데이터는 전체 데이터셋의 85%, 테스트 데이터는 15%를 차지하도록 설정
-다양한 스케일러를 사용하여 데이터를 정규화, 코드에서는 MaxAbsScaler를 사용 (스케일러별 비교 필수)
- CatBoostRegressor를 포함한 다양한 회귀 모델을 훈련하고 평가, 훈련된 모델의 예측값과 실제값을 비교하여 R2 score를 계산
- MSE(Mean Squared Error)를 계산하여 출력
- 시각화를 위해 예측값과 실제값의 산점도 그래프를 표시
- 예측 오차의 분포를 히스토그램으로 표시
- 상관계수 히트맵을 그려 데이터 간의 상관관계를 시각화
● 모델별 성능 비교
-2주간의 프로젝트를 마치며,,,
- 데이터 전처리 과정이 정말 중요하다 느꼈다... 코드를 끊임없이 만지고 개선하는것도 벅찬데, 모델 분석하고 정확도 구해내는 작업이 처음이다보니 최선의 모델 찾는것도 오래걸렸고, 짧은 시간 동안 여러 모델을 비교 분석하고 가장 높은 r2score 을 구해내는 과정이 어려웠다.
- 공휴일 데이터 조금 더 유의미 하게 묶어서 코딩 할 수 있었을 거 같은데 못해봐서 아쉬웠다
- 외부 데이터도 못 끌어와서 아쉬운 부분,, 외부 데이터 끌어왔을 때 r2score도 꼭 비교해보고 싶다
그래도 최선의 결과가 나왔어서 다행인..?
아래는 프로젝트 진행 흔적들,,,