●AI
-인공지능과 머신러닝, 딥러닝

● 딥러닝
- 일련의 단계들 또는 레이어들의 연산을 사용하는 머신러닝 알고리즘
- 레이어를 세로로 쌓았을 때 모양 때문에 깊이라고 부름
● 퍼셉트론
- 인공 신경망의 한 종류
- 뉴런의 모델을 모방하여 입력층, 출력층으로 구성한 모델
- 구성 요소: 입력값, 가중치, 활성화 함수, 출력값(예측값)
● 다층 퍼셉트론
- 딥러닝은 다층 퍼셉트론 구조에서 파생
- 명칭: 노드(node, 뉴런)는 에지라고 하는 선으로 연결
- 입력층,은닉층,출력층으로 구성
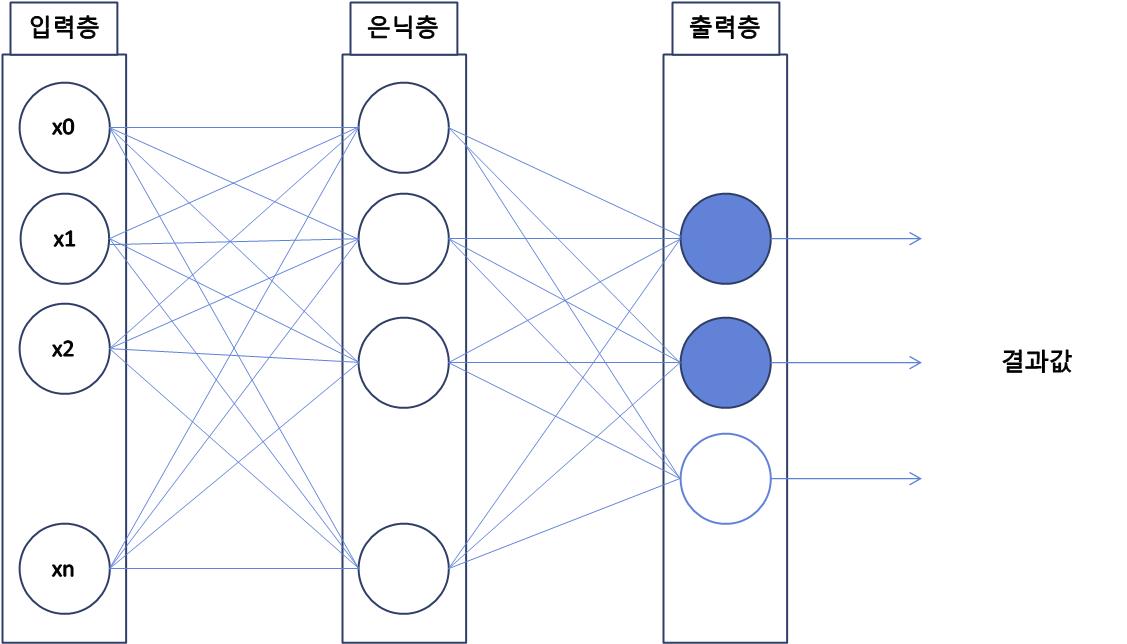
● 퍼셉트론과 다층 퍼셉트론의 차이점은?
- 은닉층의 유무
- 은닉층은 입력층과 출력층 사이에 위치하며, 입력 데이터를 여러 개의 가중치와 함께 처리하여 출력층으로 전달한다
- 은닉층을 추가함으로써, 다중 퍼셉트론은 보다 복잡한 비선형적인 관계를 모델링할 수 있다
● 코드 실습
# 1.데이터
# 2.모델구성
# 3.컴파일, 훈련
# 4.예측, 평가
# 1.데이터
import numpy as np #Numpy 라이브러리를 np로 import
x=np.array([1,2,3]) #입력데이터로 사용할 x를 NumPy 배열로 생성
y=np.array([1,2,3]) #입력데이터로 사용할 y를 NumPy 배열로 생성
from keras.models import Sequential #Keras의 Sequential 모델 클래스를 import
from keras.layers import Dense #Keras의 Dense 레이어 클래스를 import
# 2.모델구성
model = Sequential() #Sequential 모델 클래스를 이용해 model 객체를 생성
model.add(Dense(15, input_dim=1)) #입력층, 뉴런의 개수는 4, 입력 데이터의 차원은 1
model.add(Dense(30)) #히든레이어1, 은닉층을 추가, 뉴런의 개수는 30
model.add(Dense(5)) #히든레이어2, 은닉층을 추가, 뉴런의 개수는 5
model.add(Dense(3)) #히든레이어3, 은닉층을 추가, 뉴런의 개수는 3
model.add(Dense(2)) #히든레이어4, 은닉층을 추가, 뉴런의 개수는 2
model.add(Dense(1)) #출력층, 뉴런의 개수는 1
# 3.컴파일, 훈련
model.compile(loss='mse',optimizer='adam') #모델을 컴파일,손실 함수로는 평균 제곱 오차(mse)를, 옵티마이저로는 Adam을 사용
model.fit(x,y,epochs=1000) #입력 데이터(x)와 출력 데이터(y)를 이용하여 모델을 학습, epochs는 전체 데이터셋을 학습한 횟수를 뜻함
loss=model.evaluate(x,y) #학습된 모델을 이용해 입력 데이터(x)와 출력 데이터(y)에 대한 손실값을 계산
print('loss: ', loss) #2.0889956431346945e-12 #계산된 손실값을 출력
result = model.predict([4]) #학습된 모델을 이용해 새로운 입력 데이터(4)에 대한 예측값을 계산
print('4의 예측값: ', result) #3.9999957 #계산된 예측값을 출력● Numpy
- Numerical Python의 약자 , 파이썬에서 과학 계산을 위한 핵심 라이브러리
- 다차원 배열과 연산을 위한 라이브러리
- 수치 계산을 위한 다양한 함수와 메소드 제공
- 다차원 배열(ndarray) 의 사용
파이썬의 리스트와 유사하지만, ndarray는 벡터, 행렬 등 다차원 데이터의 처리 및 다양한 함수를 사용하여 데이터 빠르고 효율적 처리
● Pandas
- 데이터 처리와 분석을 위한 파이썬 라이브러리
- DataFrame 이라는 테이블 형태의 데이터 구조를 기반으로 생성
- 엑셀, csv 파일 등 다양한 파일과 데이터베이스 읽어올 수 있다
● y=wx +b (일차 함수) 일대일 대응 / w값이 (-) 일때 'mae' 사용
- 최적의 매개변수 w,b 찾는게 목적이다
입력층의 각 노드는 은닉층의 각 노드와 연결되어 대응, 이때 입력층의 각 노드는 입력 데이터의 각 feature(특성)을 나타내며, 은닉층의 노드는 입력층의 각 feature(특성)를 기반으로 한 일련의 변환(연산)을 수행
- 일대일 대응이란 입력과 출력의 관계를 정의한 것
● 입력층의 뉴런 개수와 은닉층 뉴런 개수는 상관관계가 있을까?
-> 없다입력층의 뉴런 개수는 입력 데이터의 특성에 의해 결정되고, 은니층의 뉴런 개수는 모델의 복잡도와 학습 성능에 따라 결정되기 때문, 따라서 입력 데이터의 특성 개수와 모델의 복잡도 및 학습 성능을 고려하여 적절한 뉴런 개수를 결정해야 한다
-> 뉴런의 개수는 일대일 대응이 필요하지 않음
● 출력층의 뉴런 개수대로 예측값이 출력되던데, 출력층에서 많은 예측값을 출력해 원하는 근삿값을 고르면 안되나?
- NO 예측값으로 나온 값들의 평균이 되기 때문에 의미없다
●뉴런의 개수가 정확도를 의미할 수 있는가?
- 뉴런의 개수는 모델의 복잡도와 연관이 있기에, 뉴런의 개수가 증가할수록 모델의 복잡도가 증가
모델의 성능은 입력 데이터 특성, 데이터의 양, 모델의 아키텍처, 하이퍼파라미터 설정 등 여러 요인에 영향을 받기때문에, 뉴런의 개수 증가가 모델 성능의 향상으로 이어지지 않는다
● 데이터 정확도를 위한 은닉층은 무한해도 되는가?
- 일정 수준 이상에서는 과적합(overfiting)문제가 발생한다. 훈련 데이터에 대해 정확도는 높아지지만, 세로운 데이터에 대한 예측력이 떨어지는 현상이 발생 할 수 있다. 또한 은닉층이 많아지면 연산량이 증가해 학습시간이 길어지게된다.
● 'dense' 란 무엇인가?
- keras의 층 중 하나, full connected layer을 구현하는데 사용, 입력 뉴런과 출력 뉴런이 모두 연결되어 있는 일반적인 신경망 계층
- dense 층은 뉴런의 수, 활성화 함수, 가중치 초기화 방법 등을 지정할 수 있다
입력값 * 가중치 +bias (활성화 함수 적용) = 출력값 계산
● 옵티마이저란?
- 신경망의 가중치를 학습시키는 방법을 결정하는 알고리즘
=>손실 함수를 최소화하는 가중치를 찾기 위해 사용되는 최적화 알고리즘
● 옵티마이저 종류
(위 실습 코드에선 optimizer='adam'을 사용하고 있다)
-확률적 경사 하강법(Stochastic Gradient Descent, SGD): 각 학습 단계마다 샘플의 그래디언트를 계산하여 가중치를 업데이트한다.
이 옵티마이저는 구현이 간단하고 대규모 데이터셋에도 적용 가능하며, 로컬 미니멈에 빠질 가능성이 낮다.
하지만, 수렴 속도가 느리고 지역 최소값에 빠질 가능성이 있다.
-모멘텀(Momentum): SGD에 모멘텀 항을 추가하여, 이전 학습 단계의 가중치 업데이트 방향을 고려하여 최적화 방향을 결정한다.
이 방법은 SGD보다 더 빠른 학습 속도와 좋은 일반화 성능을 가진다.
-네스테로프 가속 경사(Nesterov Accelerated Gradient, NAG): 모멘텀 방법에서 모멘텀 항을 사용하여 이전 업데이트 방향을 고려하는 것처럼, NAG는 현재 위치에서 모멘텀 방향으로 이동한 뒤 그 위치에서 그래디언트를 계산한다.
이 방법은 모멘텀 방법보다 더 나은 성능을 보인다.
-아다그라드(Adagrad): 학습률을 각 매개변수에 맞추어 조정하면서 최적화한다.
이 방법은 많은 변화가 있는 매개변수에 대해 더 작은 학습률을 적용하여 효과적으로 학습하며, 과거의 그래디언트 제곱 합을 누적하여 학습률을 조절한다.
-아다메(Adadelta): Adagrad의 단점 중 하나는 학습률이 너무 빠르게 감소하여 학습이 멈추는 것.
이를 보완하기 위해 아다메는 과거의 그래디언트 제곱 합 대신 최근 몇 번의 그래디언트 제곱 합을 이용하여 학습률을 조정한다.
-RMS프롭(RMSprop): 아다그라드와 유사하게 각 매개변수에 대해 학습률을 조절하지만, 과거의 그래디언트 제곱 합 대신 지수 이동 평균을 사용하여 학습률을 계산한다.
-아담(Adam): RMSprop과 모멘텀 방법을 합친 것으로, 학습률을 각 매개변수에 맞게 조정하면서 그래디언트의 1차 및 2차 모멘트 추정치를 유지한다.
이 방법은 대부분의 문제에서 잘 작동하며, 수렴 속도와 일반화 성능이 우수하다.
-아담 와일드(AdamW): 아담에서 가중치 감소 항을 수정하여, 일반화 성능을 더욱 향상시킨다.
이 방법은 가중치 감소와 그래디언트의 2차 모멘트 추정치를 포함하여 학습률을 각 매개변수에 맞게 조정한다.
-라드아담(RAdam): 아담에서 그래디언트의 2차 모멘트 추정치가 너무 클 때 발생하는 문제를 해결한 것으로, 변화하는 학습률과 적응형 모멘트를 사용하여 학습을 가속화한다.
-벨로시티(Velocity): SGD에 모멘텀을 추가하여 학습 속도를 높인다. 또한, 학습률을 각 매개변수에 맞게 조정하여 학습을 안정화한다.
-라지바(LaProp): 학습률과 모멘텀을 자동으로 조정하여 안정적으로 학습하도록 하는 방법. 이 방법은 SGD보다 더 높은 성능을 보입니다.
-스키마(Sketching): SGD에서 무작위 샘플링을 이용하여 모델의 일부분만 업데이트하도록 하는 방법입니다.
이 방법은 대규모 데이터셋에 효과적이며, 전체 데이터를 사용한 경우보다 더 높은 성능을 보인다.
-라듐(Radon): SGD와 모멘텀 방법의 조합으로, 그래디언트를 재생산 가능한 형식으로 저장하고 사용하여 모델을 안정적으로 학습시킨다.
-PAdam: 아담에서 파라미터 분할 방법을 사용하여 분산 학습을 지원하는 방법
-새디(SA): 아다그라드와 RMSprop의 아이디어를 결합하여, 수렴 속도와 일반화 성능을 향상시키는 방법.
이 방법은 빠른 학습 속도와 높은 성능을 보여준다.
● 만약 dim=2 라면?
- 2차원 배열, 행과 열이 있는 테이블 형태의 데이터를 나타냄
● input_shape 이란?
- input_shape은 모델의 첫 번째 층에 입력되는 데이터의 형태(shape)를 지정하는 인자
입력 데이터의 크기(shape)는 모델 구성에 중요한 역할을 한다
input_shape은 다음과 같은 방법으로 지정 가능하다
1차원 배열의 경우: input_shape=(dim,)
2차원 배열의 경우: input_shape=(dim1, dim2)
3차원 배열의 경우: input_shape=(dim1, dim2, dim3)
input_shape은 모델의 첫 번째 층에만 지정해주면 된다
● 강아지 or 고양이 를 분류하는 이진 분류에서 강아지=1, 고양이는 0일때 소수값은?
- 분류에서는 예측값 1 ~ 0.5xxxxx 사이는 강아지로 분류하게 된다
● 2차원 배열 코드 실습
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1. 데이터
x = np.array([[1,2,3,4,5,6,7,8,9,10],
[1,1,1,3,8,9,2,2,1.1,1.4]])
y = np.array([11,12,13,14,15,16,17,18,19,20])
print(x.shape)
print(y.shape)
#2. 모델구성
model = Sequential()
model.add(Dense (25, input_dim=2)) #2차원 배열
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(40))
model.add(Dense(30))
model.add(Dense(35))
model.add(Dense(29))
model.add(Dense(30))
model.add(Dense(20))
model.add(Dense(15))
model.add(Dense(12))
model.add(Dense(9))
model.add(Dense(1))
#3. 컴파일, 훈련
model.compile(loss='mse',optimizer='adam') # w값이 (-) 일때 'mae' 사용
model.fit(x,y,epochs=100, batch_size=5)
#4. 예측 평가
loss=model.evaluate(x,y) # 0.0015491764061152935
print('loss: ', loss)
result = model.predict([[10,1.4]]) #20.01144
print('10과1.6의 예측값: ', result)
● mlp 코드 실습
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1. 데이터
x = np.array([[1,2,3,4,5,6,7,8,9,10],
[1,2,1,1,2,1.1,1.2,1.4,1.5,1.6],
[10,9,8,7,6,5,4,3,2,1]])
y = np.array([11,12,13,14,15,16,17,18,19,20])
print(x.shape)
print(y.shape)
#2. 모델구성
model = Sequential()
model.add(Dense (25, input_dim=3))
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(40))
model.add(Dense(30))
model.add(Dense(35))
model.add(Dense(29))
model.add(Dense(30))
model.add(Dense(20))
model.add(Dense(15))
model.add(Dense(12))
model.add(Dense(9))
model.add(Dense(1))
#3. 컴파일, 훈련
model.compile(loss='mse',optimizer='adam')
model.fit(x,y,epochs=100, batch_size=5) #bath_size
#4. 예측 평가
loss=model.evaluate(x,y) # 1.1068251132965088
print('loss: ', loss)
result = model.predict([[10,1.6,1]]) #20.006065
print('10과1.6,0의 예측값: ', result)● batch_size 란?
- 하이퍼 파라미터
- 학습 데이터를 나누어서 몇 개의 데이터씩 묶어 학습을 진행할 것인지 정하는 파라미터이다
- batch_size가 작을 수록 모델이 더 자주 업데이트되므로 노이즈가 많은 경향, 더 많은 반복 학습이 필요
/ 안정적 + 클수록 빠르게 학습하지만 예측결과의 불확실성
>> (질문) ppt에서 배치사이즈 클 수록 학습 시간이 길어지는 경향/ 메모리 문제 ?

>>ppt 오류
● 손실함수 (Loss Functon)
- 실제값과 예측값의 차이를 비교하는 지표
- 값이 낮을수록 학습이 잘된 것
- 최적의 매개변수(가중치와 편향)를 탐색할 떄 손실 함수를 가능할 작게하는 값 찾음
- MSE : 평균 제곱 오류
출력 결과와 데이터 차이 제곱의 평균으로 정답과 오답의 모든 확률 고려
- CEE: 교차 엔트로피 오차
실제 정답의 확률만을 고려한 손실 함수 (훈련데이터의 정갑 혹은 확률이 0 or 1)
● 활성화 함수(Activation Function)
- 인공 신경망의 각 노드에서 입력 신호의 총합을 출력 신호로 변환하는 함수
- 각 층에서 입력 신호의 총합을 구한 후, 그 값을 활성화 함수에 적용하여 다음 층으로 전달
이를 통해 신경망은 비선형성을 학습 할 수 있다 + 다양한 복잡한 함수 모델링 가능
- Sigmoid/ReLU/tanh/Softmax
-Linear (선형 함수):
가장 기본적인 활성화 함수로, 입력과 동일한 값을 출력
주로 회귀(Regression) 문제에서 출력층의 활성화 함수로 사용
입력과 출력 사이의 선형 관계를 표현하기 위해 사용
ReLU (Rectified Linear Unit):
입력이 0보다 작을 경우 0을 출력하고, 0보다 큰 경우 입력 값을 그대로 출력
비선형 함수로, 신경망의 은닉층에서 주로 사용
입력에 대해 더 강한 비선형성을 제공하며, 그레이디언트 소실 문제를 완화
Sigmoid (로지스틱 시그모이드):
입력을 0과 1 사이의 값으로 압축하여 출력
이진 분류(Binary Classification) 문제에서 출력층의 활성화 함수로 사용
출력 값이 확률로 해석될 수 있어, 입력이 클래스에 속할 확률을 표현하는 데 사용
그러나 그레디언트 소실 문제와 출력 값의 제한된 범위가 있을 수 있는 단점이 존재
Softmax:
다중 클래스 분류(Multi-Class Classification) 문제에서 출력층의 활성화 함수로 사용됩니다.
입력값들을 정규화하여 클래스에 대한 확률 분포를 생성합니다.
출력 값들의 합이 1이 되며, 각 클래스에 속할 확률로 해석됩니다.
다중 클래스를 예측하고자 할 때 사용되며, Cross Entropy와 함께 사용됩니다.
● transpose / reshape
import numpy as np
a=np.array([[1,2,3],[4,5,6]])
print("Original :\n",a)
a_transpose = np.transpose(a)
print("Transpose:\n",a_transpose)
a_reshape = np.reshape(a,(3,2))
print("Reshape:\n ", a_reshape)
#transport와 reshape의 차이점은?
#transport: x,y 1대1대응 형식 축을 바꿈 reshape:배열의 형태를 바꿈
# 시배열 순서가 중요하다면 transport 인과관계가 중허다
● HW
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1. 데이터
x = np.array([[1,2,3,4,5,6,7,8,9,10],
[1,2,1,1,2,1.1,1.2,1.4,1.5,1.6],
[10,9,8,7,6,5,4,3,2,1]])
y = np.array([11,12,13,14,15,16,17,18,19,20])
print(x.shape)
print(y.shape)
#2. 모델구성
model = Sequential()
model.add(Dense (25, input_dim=3))
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(50))
model.add(Dense(40))
model.add(Dense(30))
model.add(Dense(35))
model.add(Dense(29))
model.add(Dense(30))
model.add(Dense(20))
model.add(Dense(15))
model.add(Dense(12))
model.add(Dense(9))
model.add(Dense(1))
#3. 컴파일, 훈련
model.compile(loss='mse',optimizer='adam')
model.fit(x,y,epochs=100, batch_size=5) #bath_size
#4. 예측 평가
loss=model.evaluate(x,y) # 1.1068251132965088
print('loss: ', loss)
result = model.predict([[10,1.6,1]]) #20.006065
print('10과1.6,0의 예측값: ', result)