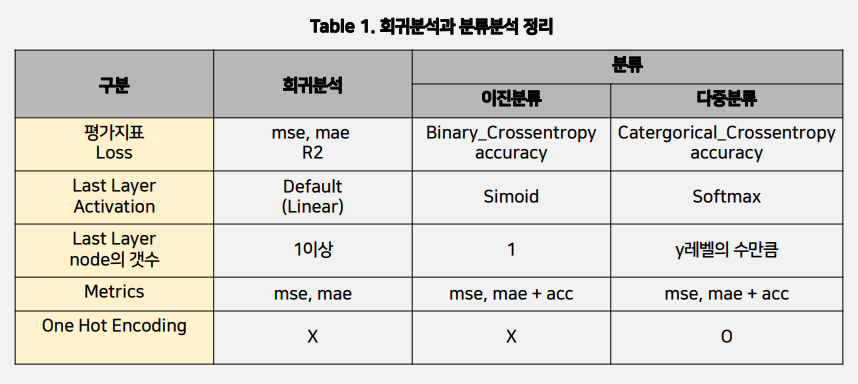
●회귀분석과 분류분석 정리
●CNN(합성곱 신경망)
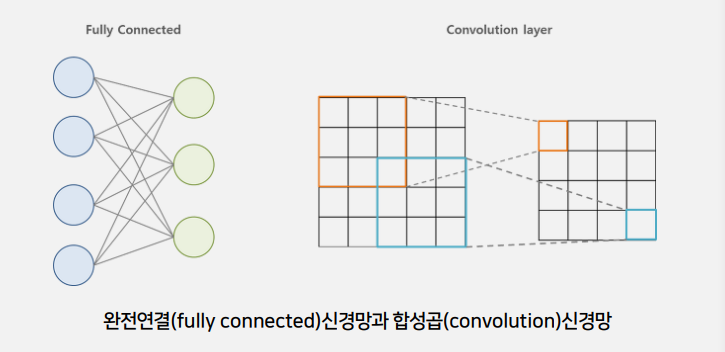
이미지 분석에서 완전연결신경망의 문제점
-데이터 형상의 무시
-변수의 개수
-네트워크의 크기
-학습시간의 문제
이미지 데이터의 경우 3차원(세로, 가로, 채널)의 형상을 가지며, 공간적 구조(spatial structure)를 지닌다
ex) 공간적으로 가까운 픽셀은 값이 비슷하거나, RGB의 각 채널은 서로 밀접하게 관련 있다
●합성곱층(Convolutional Layer, Conv Layer)
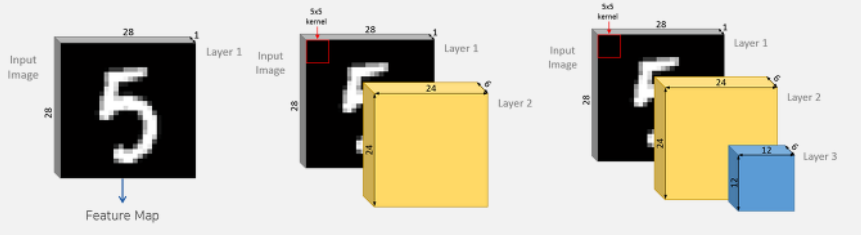
− 이미지 데이터는 일반적으로 채널, 세로, 가로 이렇게 3차원으로 구성된 데이터
− 합성곱에서는 3차원 데이터(1, 28, 28)를 입력하고 3차원의 데이터로 출력하므로 형상을 유지 가능
− CNN에서는 이러한 입출력 데이터를 특징맵(Feautre Map)이라고 함
− 합성곱층 뉴런의 수용영역(receptive field)안에 있는 픽셀 에만 연결
− 앞의 합성곱층에서는 저수준 특성에 집중하고, 그 다음 합성 곱층에서는 고수준 특성으로 조합
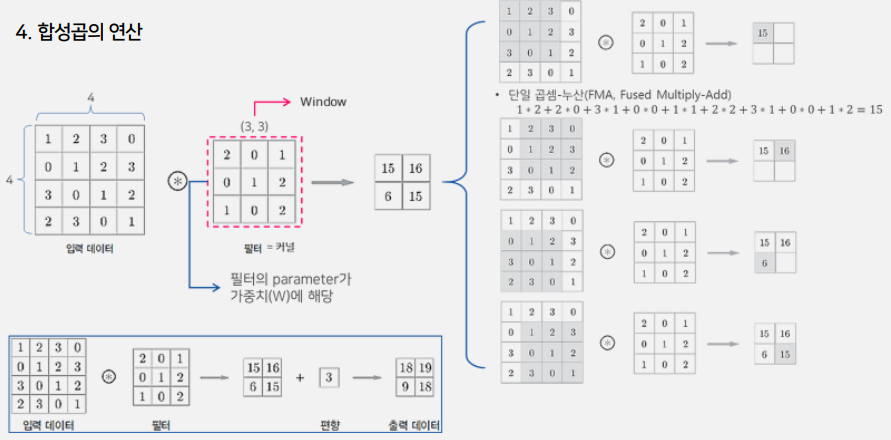
●필터

- 필터가 합성곱층에서의 가중치 파라미터(W)에 해당
- 학습단계에서 적절한 필터를 찾도록 학습
- 입력데이터에 필터를 적용하여 필터와 유사한 이미지의 영역을 강조하는 특성맵(feature map)을 출력 하여 다음 층(layer)으로 전달
●패딩(Padding)

- 데이터의 크기는 Conv Layer를 지날 때 마다 작아짐
- 가장자리 정보가 사라지는 문제 발생
- 합성곱 연산을 수행하기 전, 입력데이터 주변을 특정값 으로 채워 늘리는 것
- 주로 zero-padding을 사용함
●스트라이드(stride)
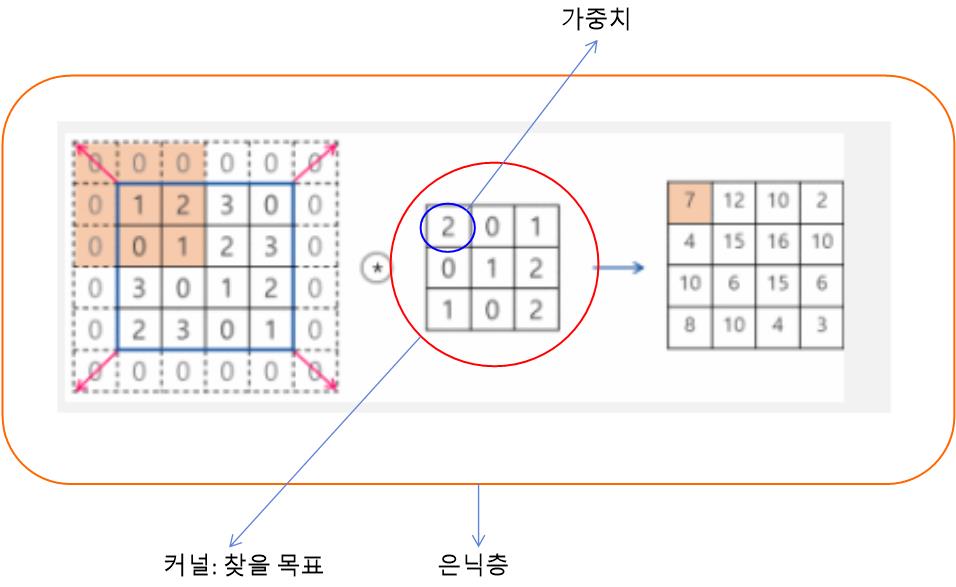
- 필터가 이동할 간격
- 출력 데이터의 크기를 조절하기 위해 사용
- 보통 1과 같이 작은 값이 더 잘 작동됨
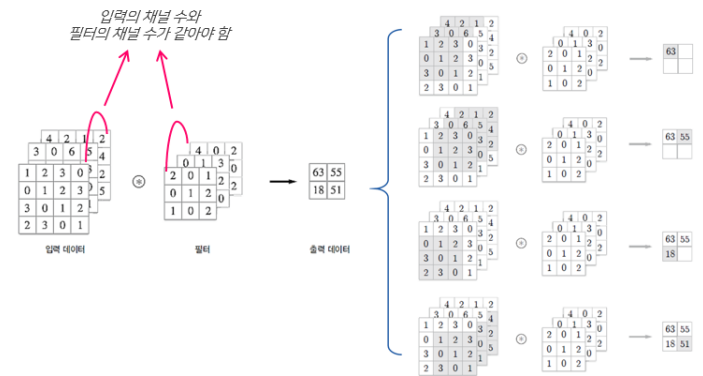
●3차원 데이터의 합성곱
●풀링층(Pooling layer)

- 그림의 사이즈를 점진적으로 줄이는 법 Max-Pooling, Average Pooling
- Max-Pooling : 해당영역에서 최대값을 찾는 방법
- Average Pooling : 해당영역에서 평균값을 계산하는 방법
위의 이미지는 2 x 2 filter로 2 stride를 적용하여 4x4 이미지를 2x2이미지로 변환한 예제
●CNN모델 및 코드
from keras.models import Sequential
from keras. layers import Dense, Conv2D, Flatten
model = Sequential ()
# model.add(Dense(units-10, input_shape-(3, )))
model.add(Conv2D (f11ters=10, kernel_size=(3, 3), # kernal_stze는 이미지를 자르는 규격을 의미
input_shape=(8, 8, 1)))
# (rows, raws, Channels)의 형태 p channels의 1은 흑백, 3은 칼라
model.add(Conv2D(7, (2, 2), activation='relu')) # model. add (Flatten ()) model. add (Dense (32, activation-'relu*)) model. add (Dense (10, activation-'softmax*))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(10, activation='softmax'))model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(4,4),
activation='relu',
input_shape = (28,28,1)))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(256))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
●Mnist



- 이미지는 0∼255 사이의 값을 갖는 28x28 크기의 NumPy array
- 이미지는 디지털화된 형태의 픽셀(pixel)들 로 구성됨.
- 각 픽셀은 0에서 255 사이의 값을 가질 수 있는데, 이는 색상의 강도(intensity)를 나타 냄 - 0 이 가장 어두운 색이며, 숫자가 높을 수록 밝은 색
●fashion_mnist

●cifar10


●cifar100



●mnist02_imshow

●fashion_mnist02


●cifar10_imshow02



●CNN/cifar100_imshow02

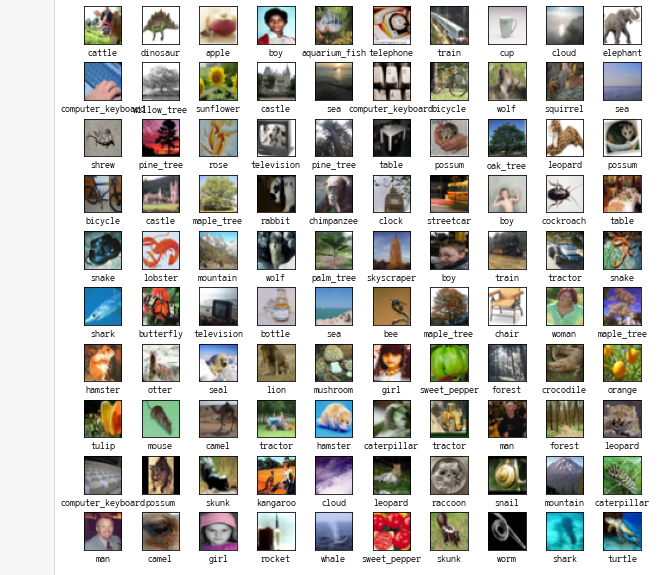
●tf01_cnn_mnist



정확도 높여주기 작업
->

●cnn_fashionMnist
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D
from keras.datasets import fashion_mnist
#1. 데이터
(x_train, y_train), (x_test, y_test)= fashion_mnist.load_data()
#print(x_train.shape, y_train.shape) #(60000, 28, 28) (60000,)
#print(x_test.shape, y_test.shape) #(10000, 28, 28) (10000,)
# 정규화
x_train, x_test = x_train/255.0, x_test/255.0
# reshape
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#[실습]
model=Sequential()
model.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(28,28,1)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128,activation='relu'))
model.add(Dense(10, activation='softmax'))
#컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=256)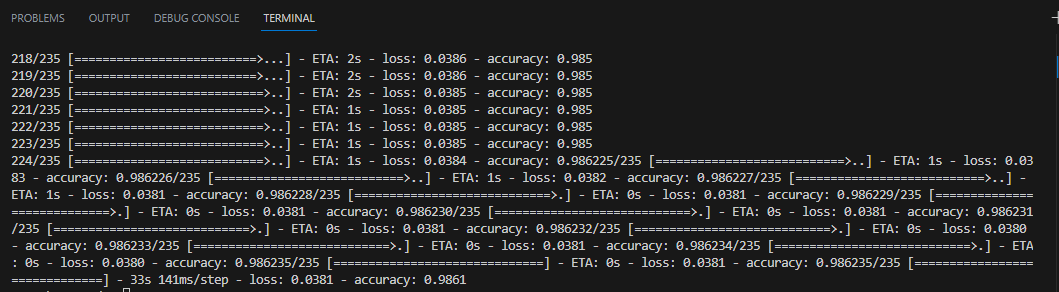
●maxpooling (maxpooling, dropout 추가)
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D,Dropout
from keras.datasets import fashion_mnist
#1. 데이터
(x_train, y_train), (x_test, y_test)= fashion_mnist.load_data()
#print(x_train.shape, y_train.shape) #(60000, 28, 28) (60000,)
#print(x_test.shape, y_test.shape) #(10000, 28, 28) (10000,)
# 정규화
x_train, x_test = x_train/255.0, x_test/255.0
# reshape
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#[실습]
model=Sequential()
model.add(Conv2D(filters=32, kernel_size=(4,4), activation='relu', input_shape=(28,28,1)))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128,activation='relu'))
model.add(Dense(10, activation='softmax'))
#컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=256)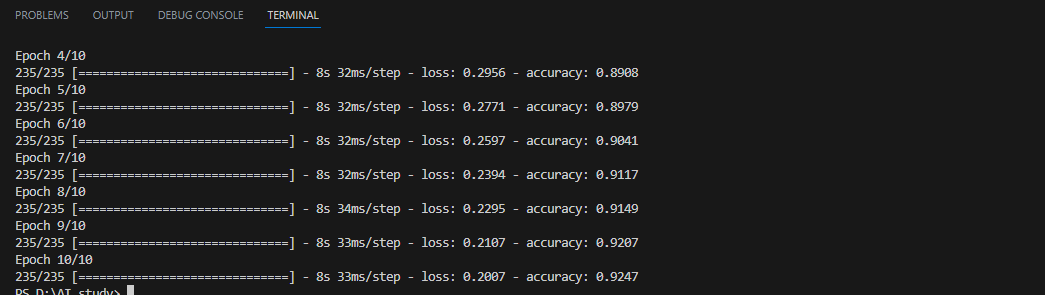
●cifar10_maxpooling
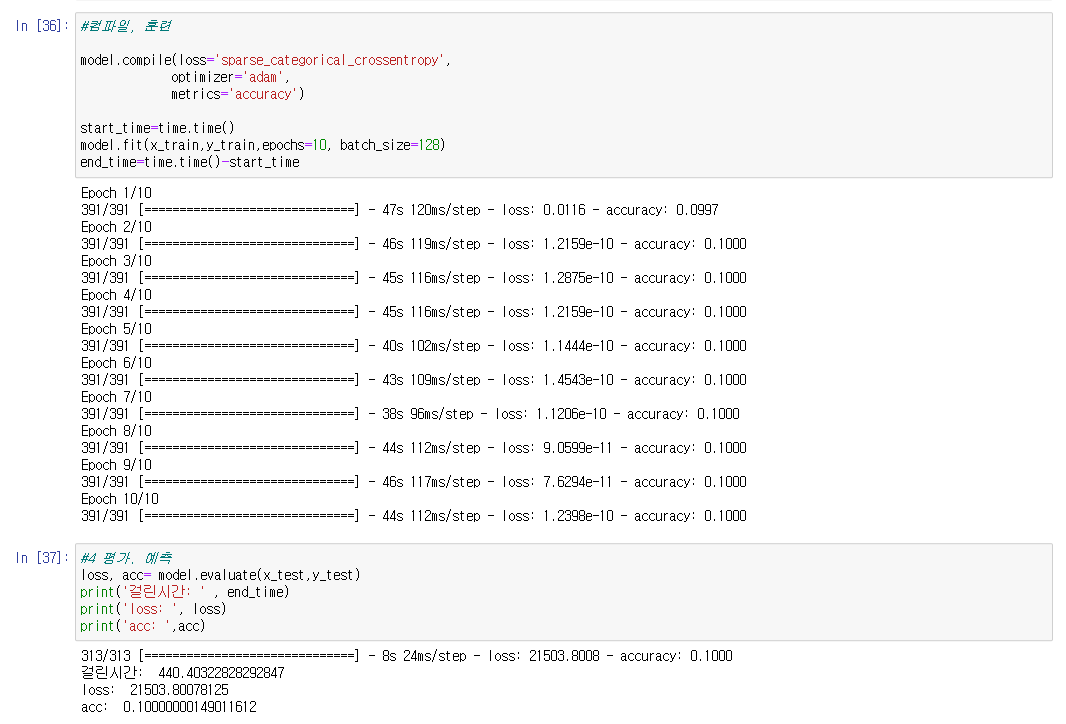
●cifar100 maxpooling
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Dropout
from keras.datasets import cifar100
import time
#1 데이터
(x_train, y_train), (x_test,y_test) = cifar100.load_data()
#print(x_train.shape, y_train.shape)
#print(x_test.shape, y_test.shape)
#정규화
x_train = x_train/255.0
x_test=x_test/255.0
#2 모델구성
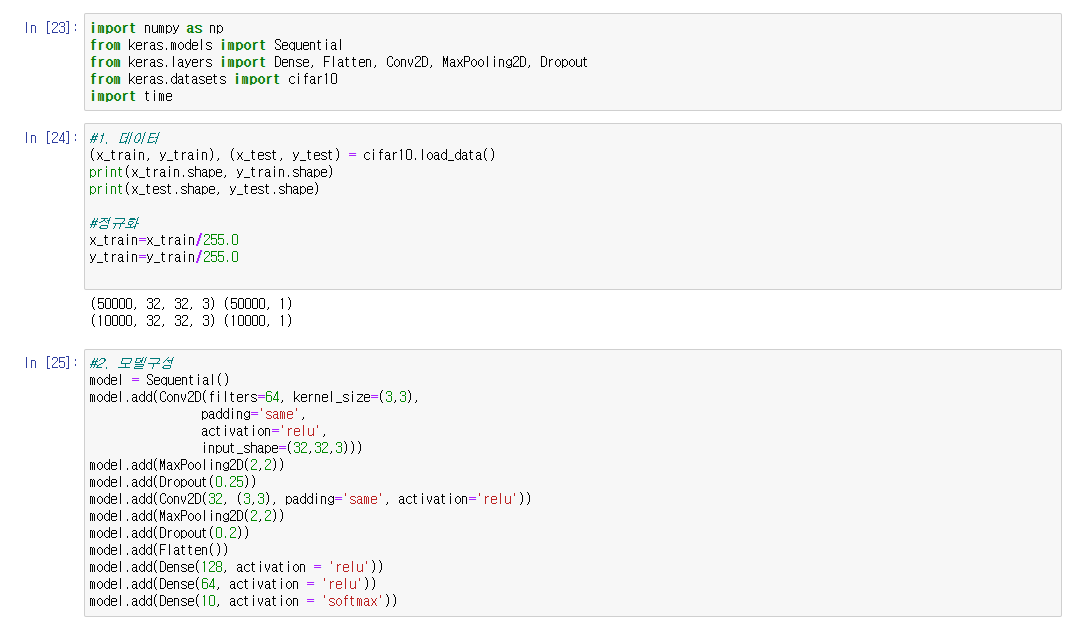
model=Sequential()
model.add(Conv2D(filters=64, kernel_size=(3,3),
padding='same',
activation='relu',
input_shape=(32,32,3)))
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.25))
model.add(Conv2D(128,(3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(100, activation='softmax'))
#컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics='accuracy')
start_time=time.time()
model.fit(x_train, y_train, epochs=10, batch_size=256)
end_time= time.time()-start_time
#평가 예측
loss, acc= model.evaluate(x_test,y_test)
print('걸린시간: ' , end_time)
print('loss: ', loss)
print('acc: ',acc)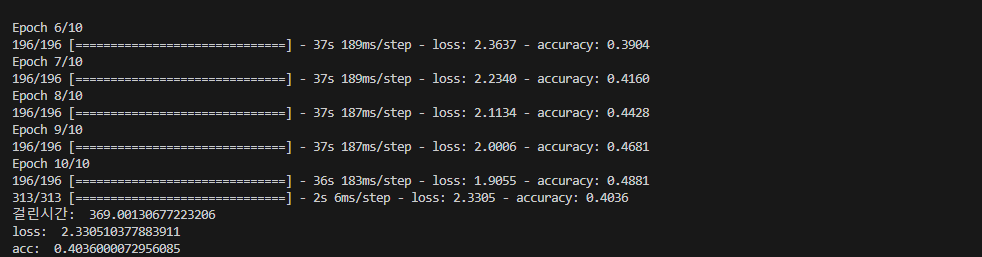
▶너무 높은 loss와 부정확도 때문에 코드를 좀 더 정확하게 나오게 해보려고 고쳐보았다
단, 시간이 너무 오래걸려 동일 조건에서 cifar100 -> cifar10로 바꾼채로 진행해 보았다
목표: acc 7.7 이상
1. dropout: 0.25 -> 0.2
2. dropout: 0.4 -> 0.2
3. epochs: 30
4 batch_size=256

결과
#loss: 1.3285537958145142
#acc: 0.7423999905586243
#걸린시간: 1084.8667232990265
▶정확도가 조금 향상되었지만, 여전히 목표치엔 미달
1. dropout: 0.2 -> 0.3
2. dropout: 0.2 -> 0.6
3. epochs: 30
4 batch_size=256

결과
# loss: 0.9203954339027405
#acc: 0.7566999793052673
#걸린시간: 1080.484658241272
▶MaxPooling 아래의 dropout 크기 증가가 정확도와 연관이 있는거같다 , 조금 더 나아진 정확도
1. dropout: 0.3 -> 0.2
2. dropout: 0.6 -> 0.7
3. epochs: 50
4 batch_size=256
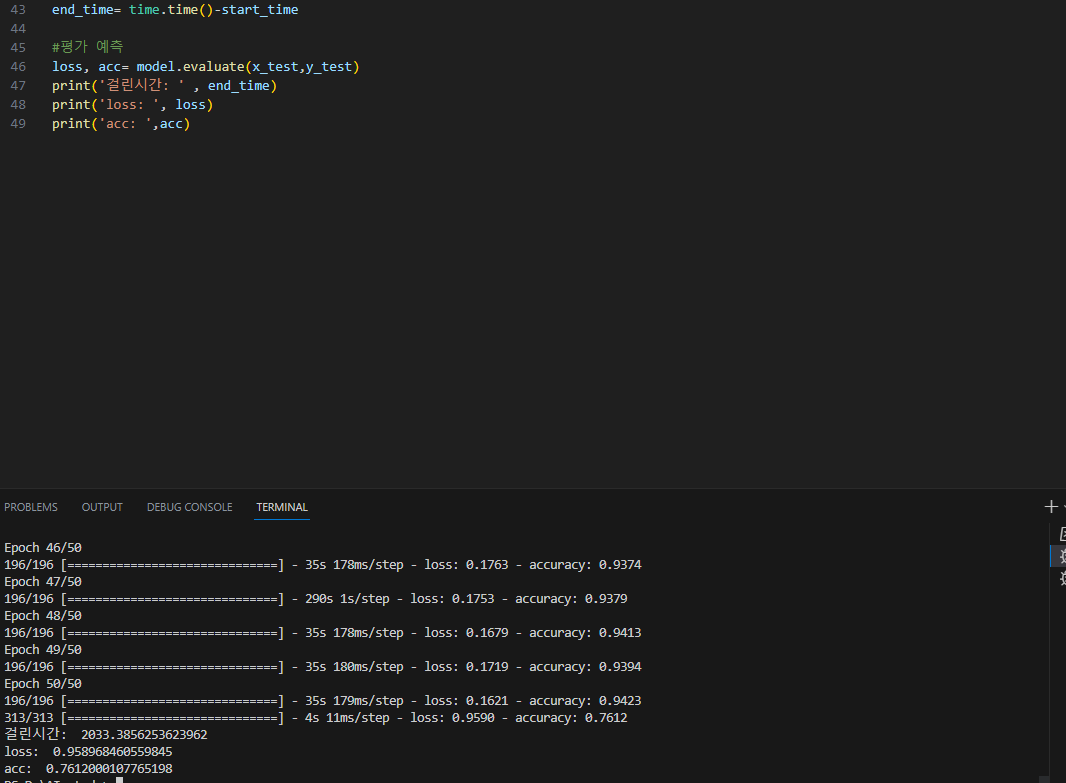
결과
# loss: 0.958968460559845
#acc: 0.7612000107765198
#걸린시간: 2033.3856253623962
▶epochs의 증가, MaxPooling 위의 dropout 크기감소, MaxPooling 아래의 dropout 증가가 모두 영향을 끼친거같다 조금 더 성능 향상을 이뤘다, 다음 실행에선 batch_size를 줄여 정확도를 더 높여봐야겠다
★성공 (#acc: 0.7836999893188477)
1 dropout: 0.20 -> 0.1
2 dropout: 0.7 -> 0.8
3 epochs: 50
4 batch_size: 256 -> 128
mport numpy as np
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Dropout
from keras.datasets import cifar10
import time
#1 데이터
(x_train, y_train), (x_test,y_test) = cifar10.load_data()
#print(x_train.shape, y_train.shape)
#print(x_test.shape, y_test.shape)
#정규화
x_train = x_train/255.0
x_test=x_test/255.0
#2 모델구성
model=Sequential()
model.add(Conv2D(filters=64, kernel_size=(3,3),
padding='same',
activation='relu',
input_shape=(32,32,3)))
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.10)) #0.25 -> 0.1
model.add(Conv2D(128,(3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Dropout(0.80)) #0.2 -> 0.8
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
#컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics='accuracy')
start_time=time.time()
model.fit(x_train, y_train, epochs=50, batch_size=128)
end_time= time.time()-start_time
#평가 예측
loss, acc= model.evaluate(x_test,y_test)
print('걸린시간: ' , end_time)
print('loss: ', loss)
print('acc: ',acc)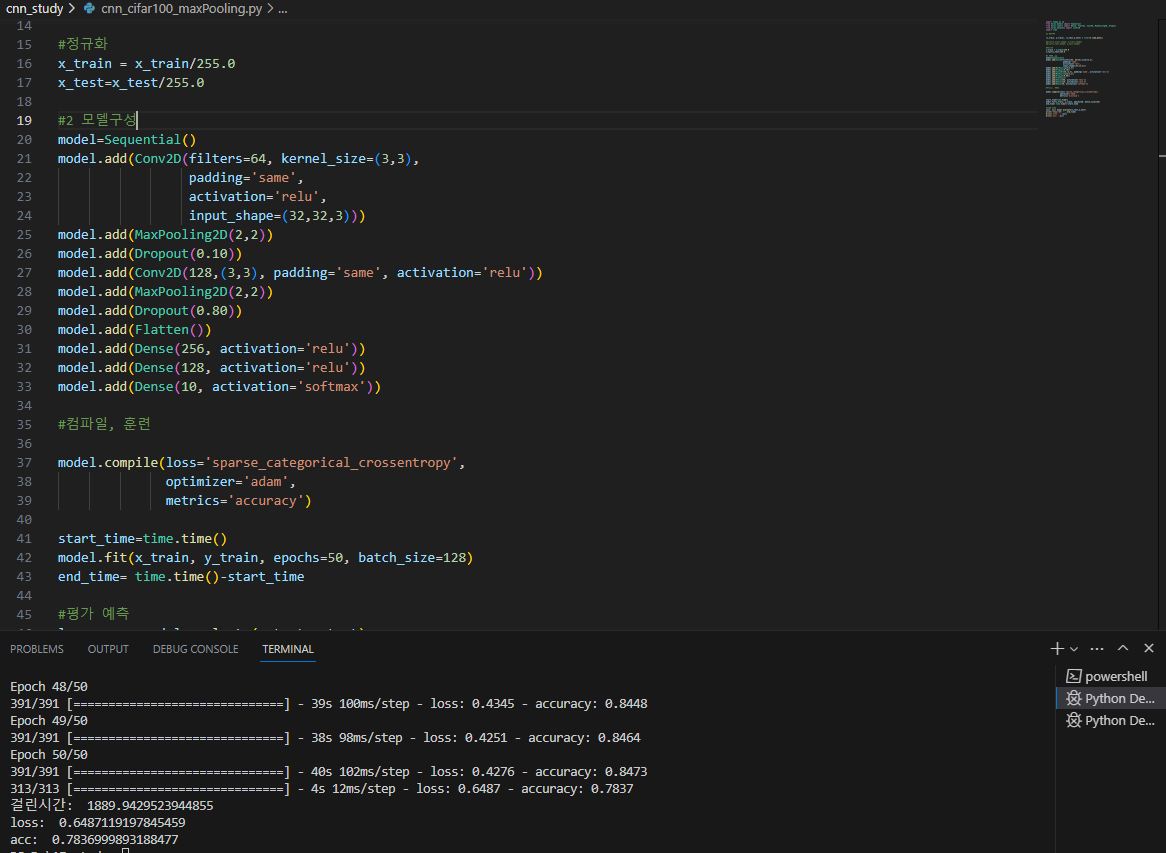
결과
# loss: 0.6487119197845459
#acc: 0.7836999893188477
#걸린시간: 1889.9429523944855
▶목표 달성
epochs의 증가, MaxPooling 위의 dropout 크기감소, MaxPooling 아래의 dropout 증가. batch_size 감소가 모두 영향을 끼친거같다
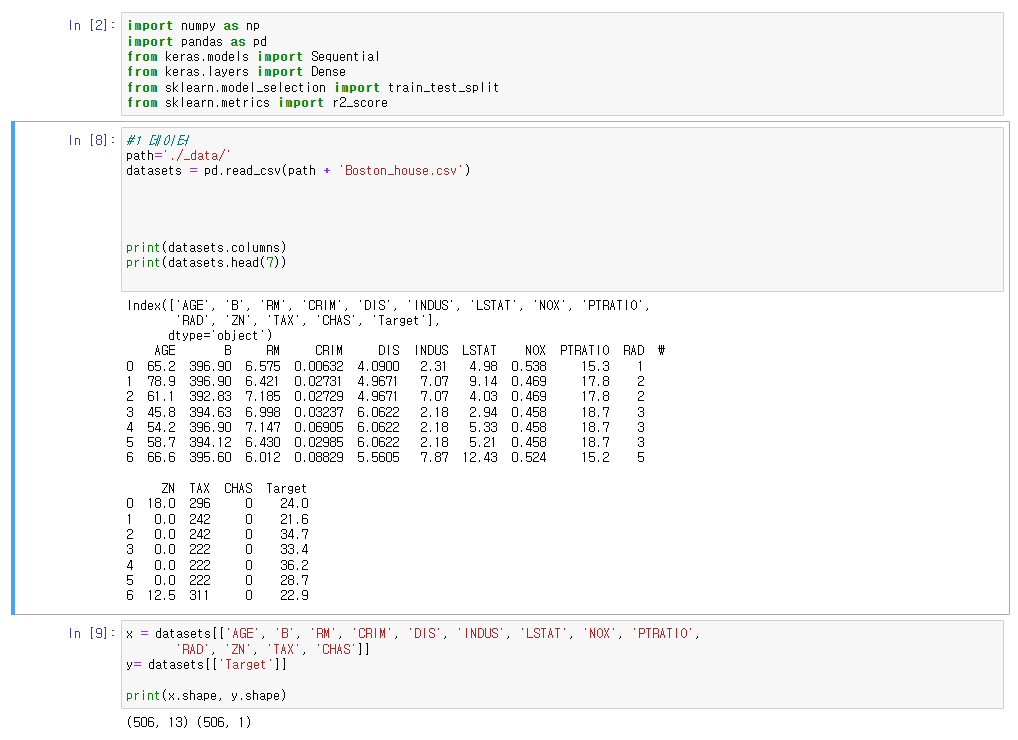
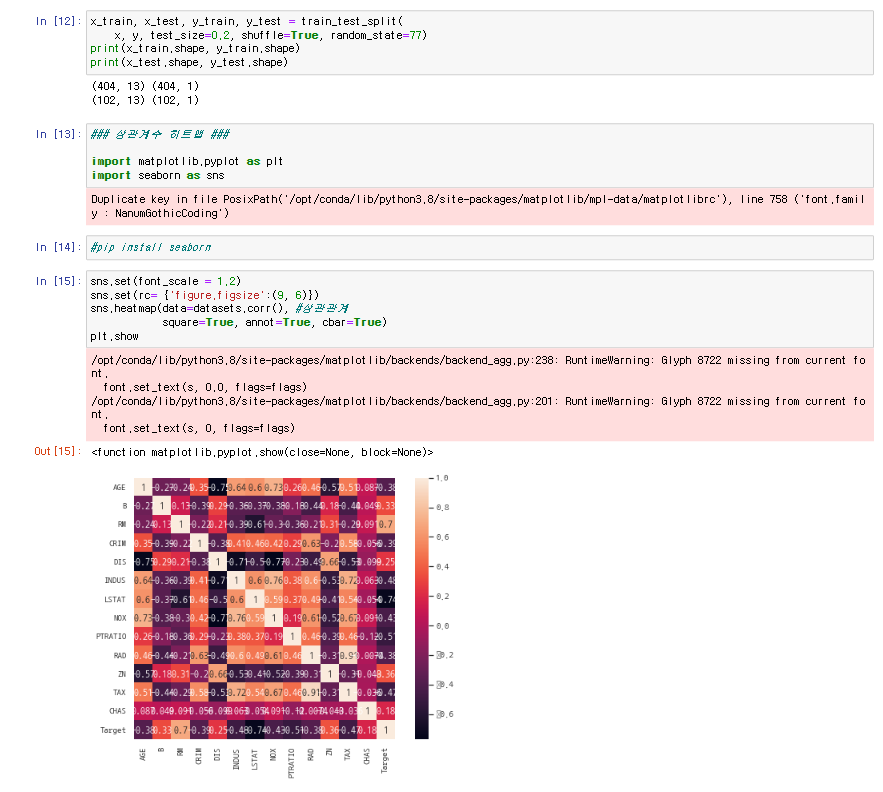
●pandas
●pandas_boston data