● Gradient Descent (경사하강법)
-함수의 기울기(=gradient)를 이용해 x의 값을 어디로 옮겼을 때 함수가 최소값을 찾는지 알아보는 방법
=> 문제점
1. 극소값(local minimum)에 도달할 수 있다는 것이 증명되었으나, 전체 최소값(global minimum) 에 갈 수 있다는 보장 없음
2. 훈련이 느림
● Momentum
-GD(graient descent) 의 문제를 해결하기 위해 보편적으로 사용되는 방법
-관성(momentum)을 적용하여 변수가 가던 방향으로 계속 가도록 속도(velocity)를 추가한 것
-전체 최소값(global minimum)에 이르기전에 기울기가 0이 되는 (local minimum)에 빠지는 것을 방지
=>문제점
1. 여전히 지역 최소값 탈출이 어렵다
2. 수렴 속도의 불안정성
3. 메모리 요구량 증가
4. 하이퍼 파라미터 설정의 어려움
● AdaGrad
- 관성(momentum)은 gradient의 방향에 초점을 두었다면, AdaGrad는 step size에 초점
이미 학습이 많이 된 변수는 학습을 느리게, 학습이 아직 덜 된 드물게 등장한 변수라면 학습을 더 빨리 훈련함
=>문제점
학습이 오래 진행이 될 경우 step size가 너무 작아져서 거의 움직이지 않는 상태가 됨
● RMSProp
- Root Mean Square Propatation의 약자 Adagrad의 계산식에 지수 가중 이동 평균(Exponentially weighted average)를 사용하여 최신 기울기들이 더 크게 반영되도록 함
=>문제점
1. 여전히 하이퍼 파라미터 설정에 민감
2. 지역 지역 최소값에 빠질 수 있는 가능성 존재
● Adam
- Adam(Adaptive Moment Estimation) 은 RMSProp과 Momentum 방식을 융합
- Momentum과 유사하게 지금까지 계산한 기울기의 지수 평균을 저장하며, RMSProp과 유사하게 기울기의 제곱값의 지수 평균을 저장
=>문제점
1. 메모리 요구량이 큼
2. 학습률 조절이 자동으로 이루어지기에 학습률 감소 패턴 파악이 어려움
● 과적합(Overfitting)

- 과적합은 모델이 학습 데이터에 너무 과도하게 적합화되어, 새로운 데이터에 대한 예측 성능이 저하되는 현상
- 모델이 학습 데이터에만 맞추어져 새로운 데이터에 대해 일반화(generalization) 능력이 부족하게 되는 것
#초록색 선은 과적합된 모델을, 검은색 선은 일반 모델
● Early Stopping
- 과적합을 방지하기 위한 방법 중 하나
- 학습 중 모델의 성능을 모니터링하다가 학습 데이터에 대한 성능은 계속해서 향상되지만 검증 데이터에 대한 성능은 향상되지 않거나 감소하는 지점에서 학습을 조기 종료하는 것
- 일반적으로, 학습 데이터와 검증 데이터를 나누어 학습하면서 적용됨
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
#from sklearn.datasets import load_boston # 윤리적 문제로 제공 안함
from sklearn.datasets import fetch_california_housing
import time
#1 데이터
#daatsets = load_boston()
datasets = fetch_california_housing()
x= datasets.data #x축 변수 컬럼
y= datasets.target #집값
print(datasets.feature_names)
#MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude
print(datasets.DESCR)
#- 블럭 그룹의 중위수 소득
#- 블럭 그룹의 주택 연령 중위수
#- 가구당 평균 객실 수
#- 평균 가구당 침실 수
#- 모집단 블럭 그룹 모집단
#- 평균 가구원수
#- 블록 그룹 위도
#- 경도 블록 그룹 경도
print(x.shape) #(20640, 8)
print(y.shape) #(20640,)
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle=True
)
print(x_train.shape)
print(y_train.shape)
#2 모델 구성
model= Sequential()
model.add(Dense(100, input_dim=8))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(1))
#3 컴파일
model.compile(loss='mse', optimizer='adam')
##ealry stopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor='val_loss', patience=100, mode='min',
verbose=1, restore_best_weights=True) # restore_best_weights 는 디폴트(기본값)이 False이므로 True로 변경필수
start_time = time.time()
hist= model.fit(x_train, y_train, epochs=500, batch_size=200,
validation_split=0.2, callbacks=[earlyStopping], verbose=1) #validation_data =>0.2 (train:0.6 / test:0.2)
end_time = time.time() - start_time
#4 평가 예측
loss = model.evaluate(x_test, y_test)
print('loss: ', loss)
y_predict = model.predict(x_test)
r2= r2_score(y_test,y_predict)
print('r2 스코어: ' ,r2)
print('end time:' ,end_time)
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker = '.' , c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker= '.', c='blue' ,label='val_loss')
plt.title('loss & val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
● 라이브러리 충돌 오류 해결 코드
# 자주뜨는 라이브러리 충돌 오류 고치는 코드
import os
os.environ['KMP_DUPLICATE_LIB_OK'] ='True'
● 실습 코딩
# validation01
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
#x= np.array(range(1,21))
#y= np.array(range(1,21))
'''
#데이터 쉐입보기
print (x.shape)
print (y.shape)
'''
x_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
y_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
x_test = np.array([17,18,19,20])
y_test = np.array([17,18,19,20])
x_val = np.array([13,14,15,16])
y_val = np.array([13,14,15,16])
#2 모델 구성
model= Sequential()
model.add(Dense(14, input_dim=1))
model.add(Dense(50))
model.add(Dense(1))
#3 컴파일 훈련
model.compile(loss='mse', optimizer='adam')
model.fit(x_train, y_train, epochs=100, batch_size=1,
validation_data=[x_val, y_val])
#4 평가,예측
loss = model.evaluate(x_test, y_test)
print('loss: ', loss)
result = model.predict([21])
print('21의 예측값: ', result)
# validation02
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
#1 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20])
#x= np.array(range(1,21))
#y= np.array(range(1,21))
'''
#데이터 쉐입보기
print (x.shape)
print (y.shape)
'''
x_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
y_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
x_test = np.array([17,18,19,20])
y_test = np.array([17,18,19,20])
x_val = np.array([13,14,15,16])
y_val = np.array([13,14,15,16])
#2 모델 구성
model= Sequential()
model.add(Dense(14, input_dim=1))
model.add(Dense(50))
model.add(Dense(1))
#3 컴파일 훈련
model.compile(loss='mse', optimizer='adam')
hist = model.fit(x_train, y_train, epochs=100, batch_size=1,
validation_data=[x_val, y_val])
#4 평가,예측
loss = model.evaluate(x_test, y_test)
print('loss: ', loss)
result = model.predict([21])
print('21의 예측값: ', result)
##history_val_loss 출력 출력하는 이유: 나중에 ealrystop 시 val loss 최소화 지점에서 멈춰야하므로
print('==================================================================================')
print(hist)
#print(hist.history)
print(hist.history['val_loss'])
## loss 와 val_loss 시각화
import matplotlib.pyplot as plt
import os # 자주뜨는 라이브러리 충돌 오류 고치는 코드
os.environ['KMP_DUPLICATE_LIB_OK'] ='True'
'''
from matplotlib import font_manager, rc
font_path = 'C:\Windows\Fonts/Calibri.ttf'
font = font_manager.FontProperties(fname=font_path).get_name()
rc('font', family=font)
'''
#plot:선 scatter:점
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'],marker='.', c='red', label='loss')
plt.plot(hist.history['val_loss'],marker='.', c='blue', label='val_loss')
plt.title('0')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
#iris_validation
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
import time
# 데이터
datasets = load_iris()
print(datasets.DESCR)
print(datasets.feature_names)
x=datasets['data'] # =x=datasets.data
y= datasets.target
print(x.shape, y.shape) #(150, 4) (150,)
### one hot encoding
from keras.utils import to_categorical
y = to_categorical(y)
print(y)
print(y.shape)
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
print(x_train.shape, y_train.shape) #(105, 4) (105,)
print(x_test.shape, y_test.shape) #(45, 4) (45,)
print(y_test)
#2 모델 구성
model = Sequential()
model.add(Dense(100, input_dim=4))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(3,activation='softmax'))
#3 컴파일 + 훈련
model.compile(loss='categorical_crossentropy',
optimizer= 'adam',
metrics=['accuracy'])
start_time = time.time()
hist = model.fit(x_train, y_train, epochs=500, batch_size=100,
validation_split= 0.3)
end_time = time.time() - start_time
print('걸린시간: ', end_time)
#4 평가예측
loss,acc = model.evaluate(x_test, y_test)
print('loss: ', loss)
print('acc: ',acc)
import matplotlib.pyplot as plt
plt.figure(figsize=(9,6))
plt.plot(hist.history['loss'], marker = '.' , c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker= '.', c='blue' ,label='val_loss')
plt.title('iris loss & val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()
●Save model
-model.save() 함수는 모델의 구조와 가중치를 함께 저장
따라서 해당 함수를 호출하는 위치에 따라 저장되는 내용이 달라진다
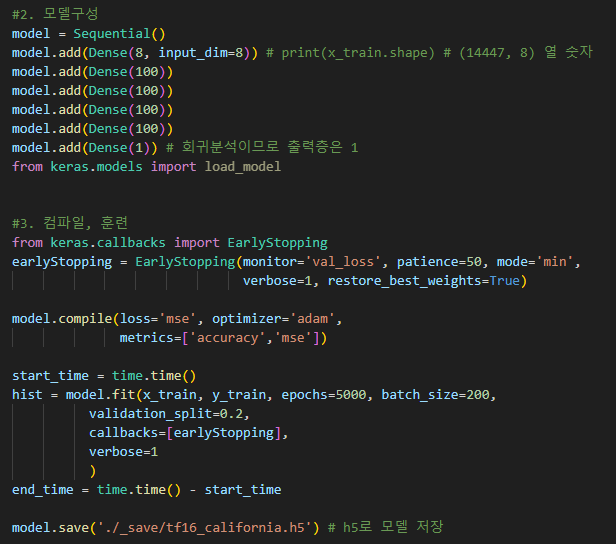
-만약 model.save()를 model.compile() 이후, model.fit() 이전, 즉 모델 구성이 완료된 후에 호출한다면,그 시점의 모델 구조와 초기화된 가중치(훈련 전이므로 무작위로 초기화된 값)가 저장된다
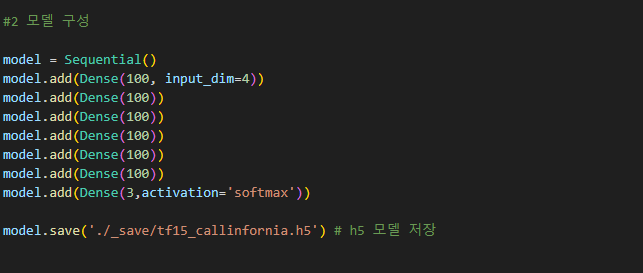

위 코드에서 (''' '''') 로 주석 처리 된 부분이 model.save 함수가 저장하는 가중치 영역이다
만약 model.save()를 model.fit() 이후에 호출한다면, 그 시점의 모델 구조와 훈련된 가중치가 함께 저장된다
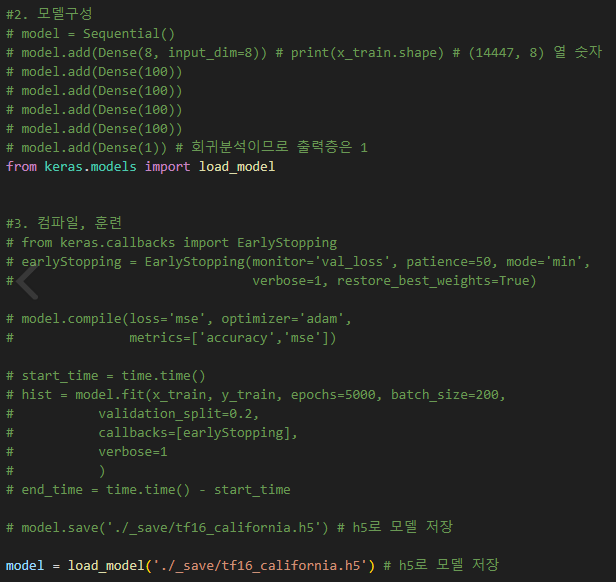
●Save weight

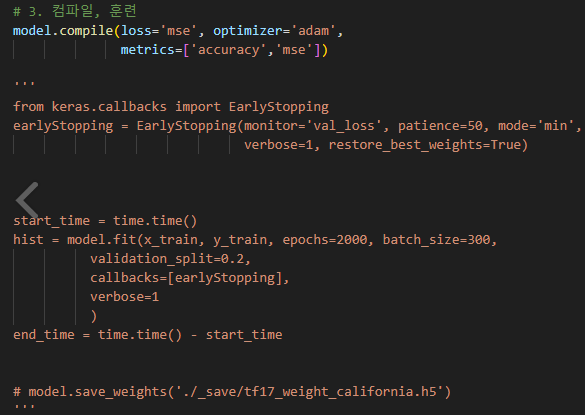
모델의 가중치를 저장하기 위해서는 model.save_weights(filepath) 함수를 사용
여기서 filepath는 가중치를 저장할 경로를 나타낸다
저장된 가중치는 model.load_weights(filepath) 함수를 사용하여 다시 로드할 수 있다
위 코드에서 주석처리한 부분이 model.save_weights 함수가 저장하는 가중치 영역
●Model Check Point
-Keras에서 제공하는 콜백(callback) 중 하나, 훈련 중간에 모델의 가중치 또는 전체 모델을 저장할 수 있다
-이를 통해 훈련 과정에서 얻은 최적의 가중치 또는 모델을 자동으로 저장, 훈련이 중단되거나 완료된 후에도 최적의 결과를 사용
-일반적으로 ModelCheckpoint는 model.fit()의 callbacks 매개변수를 통해 사용, 이렇게 사용하면 에폭(epoch)이 끝날 때마다 모델이 저장된다
+저장할 모델의 조건을 설정할 수 있다(ex) 검증 성능이 개선될 때만 저장)
from tensorflow.keras.callbacks import ModelCheckpoint
# ModelCheckpoint 콜백 생성
checkpoint = ModelCheckpoint(filepath='best_model.h5', monitor='val_loss', save_best_only=True, mode='min')
# 훈련 중 최적의 모델을 저장하기 위해 ModelCheckpoint 콜백 사용
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_val, y_val), callbacks=[checkpoint])