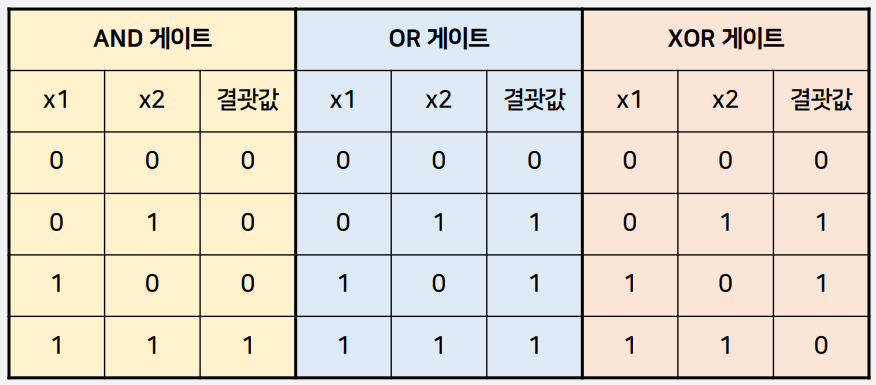
● 퍼셉트론의 과제 - XOR 문제
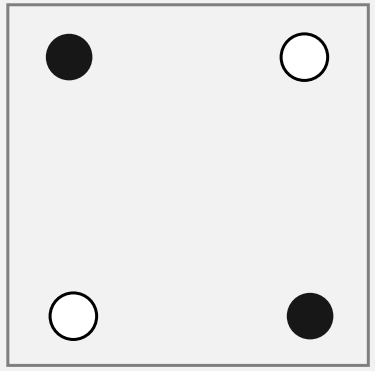
- 직선을 하나 그어서 직선의 한쪽 편에는 검은 점, 다른 한쪽에는 흰 점만 있도록 할 수 있을까?
->이것이 퍼셉트론의 한계를 설명할 때 등장 하는 XOR(exclusive OR) 문제
- AND, OR, XOR 게이트
● SVM 모델
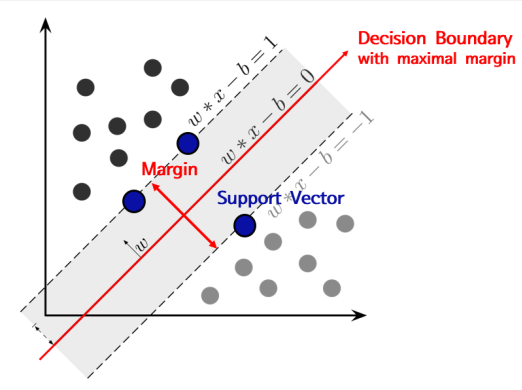
- 서포트 벡터 머신은 여백(Margin)을 최대화하는 지 도 학습 알고리즘
- 여백(Margin)은 주어진 데이터가 오류를 발생시키 지 않고 움직일 수 있는 최대 공간
- 분류를 위한 서포트 벡터 머신 SVC
- 회귀를 위한 서포트 벡터 머신 SVR
● Decision Tree

- 분류와 회귀 문제에 널리 사용하는 모델
- 기본적으로 결정 트리는 결정에 다다르기 위해 예/아니오 질문을 이어 나가면서 학습

-scikit-learn에서 결정 트리는 DecisionTreeRegressor와 DecisionTreeClassifier에 구현되어 있다
●Random Forest
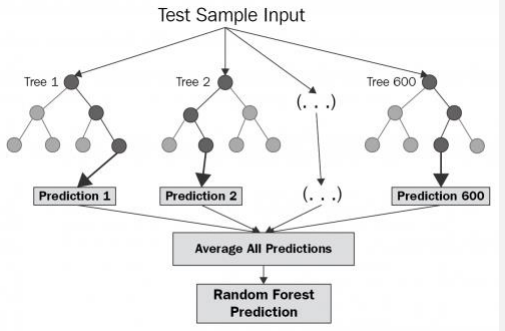
- 여러 개의 결정 트리들을 임의적으로 학습하는 방식 의 앙상블 방법
- 여러가지 학습기들을 생성한 후 이를 선형 결합하여 최종 학습기를 만드는 방법
- 특징 :
임의성: 서로 조금씩 다른 특성의 트리들로 구성
비상관화: 각 트리들의 예측이 서로 연관되지 않음
견고성: 오류가 전파되지 않아 노이즈에 강함
일반화: 임의화를 통한 과적합 문제 극복
●부스팅 (Boosting)
- Boosting 이란?
-약한 분류기를 결합하여 강한 분류기를 만드는 과정
- 각 0.3의 정확도를 가진 A, B, C를 결합하여 더 높은 정확도, 예를 들어 0.7 정도의 accuracy를 얻는 게 앙상블 알고리즘의 기본 원리
- Boosting은 이 과정을 순차적으로 실행 A 분류기를 만든 후, 그 정보를 바탕으로 B 분류기를 만들고, 다시 그 정보를 바탕으로 C 분류기를 만듦
● Adaptive Boosting (AdaBoost)
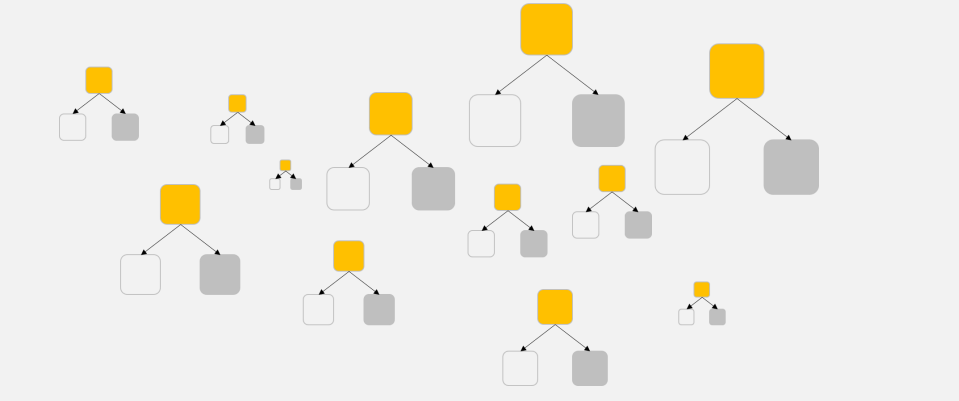
- 다수결을 통한 정답 분류 및 오답에 가중치 부여
● Gradient Boosting Model (GBM)
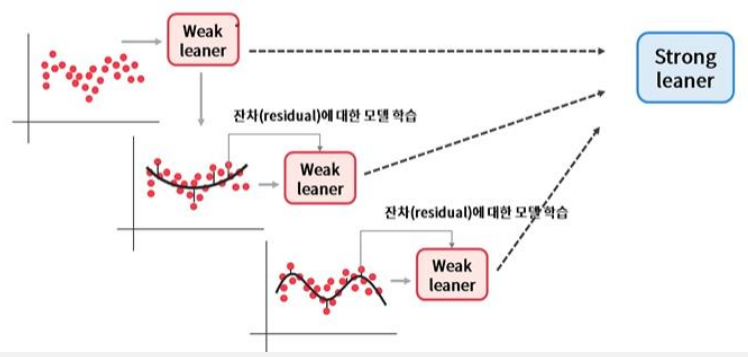
- Loss Function의 gradient를 통해 오답에 가중치 부여
- LightGBM, CatBoost, XGBoost - Gradient Boosting Algorithm을 구현한 패키지
● K-Fold
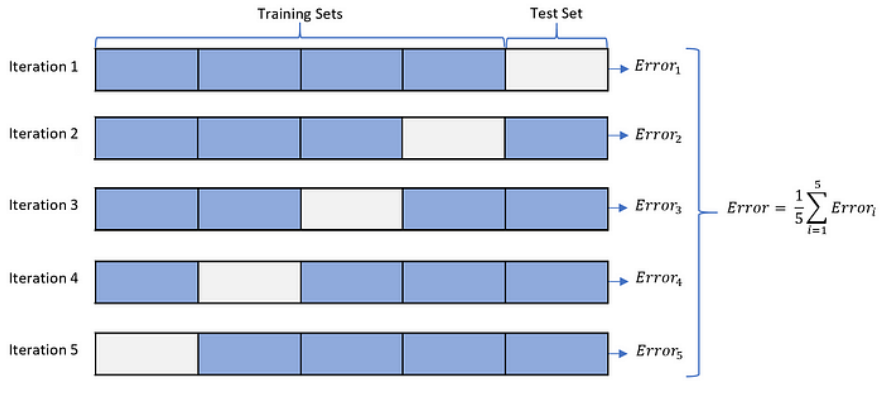
- ML 모델에서 가장 보편적으로 사용되는 교차 검증 기법
- K개의 데이터 폴드 세트를 만들어서 K번만큼 각 폴드 세트에 학습과 검증 평가를 수행
- 회귀 문제에서의 교차 검증 .
StratifedKFold
- 레이블 데이터가 왜곡되었을 경우
- 일반적으로 분류에서의 교차 검증
● 스케일링 (Scaling)
- Normalization (정규화)
- 특성들을 특정 범위(주로 [0,1]) 로 스케일링 하는 것
- 가장 작은 값은 0, 가장 큰 값은 1 로 변환되므로, 모든 특성들은 [0, 1] 범위를 갖게 됨
- Standardization (표준화)
- 특성들의 평균을 0, 분산을 1 로 스케일링 하는 것
- 즉, 특성들을 정규분포로 만드는 것 주의사항
- 훈련 데이터에는 fit_transform() 메서드를 적용
- 테스트 데이터에는 transform() 메서드를 적용
- 주의사항
- 훈련 데이터에는 fit_transform() 메서드를 적용
- 테스트 데이터에는 transform() 메서드를 적용
● MinMaxScaler()
- Min-Max Normalization 이라고도 불리며 특성들을 특정 범위([0,1]) 로 스케일링
- 이상치에 매우 민감하며, 분류보다 회귀에 유용함
● StandardScaler()
- 특성들의 평균을 0, 분산을 1 로 스케일링 즉, 특성들을 정규분포로 만드는 것
- 이상치에 매우 민감하며, 회귀보다 분류에 유용함
● MaxAbsScaler()
- 각 특성의 절대값이 0 과 1 사이가 되도록 스케일링
- 즉, 모든 값은 -1 과 1 사이로 표현되며, 데이터가 양수일 경우 MinMaxScaler 와 동일함
●RobustScaler()
- 평균과 분산 대신에 중간 값과 사분위 값을 사용
- 이상치 영향을 최소화할 수 있음
●실습 코드
# xor
import numpy as np
from sklearn.linear_model import Perceptron
from sklearn.svm import SVC, SVR ,LinearSVC, LinearSVR
from sklearn.metrics import accuracy_score
#1. 데이터
x_data = [[0,0], [0,1], [1,0], [1,1]]
y_data = [0, 1, 1, 0]
#2. 모델
model= Perceptron()
#3.훈련
model.fit(x_data,y_data)
#4 평가,예측
result = model.score(x_data,y_data)
y_predict = model.predict(x_data)
acc= accuracy_score(y_data, y_predict)
print('모델의 score:' , result)
print(x_data, '의 예측결과' , y_predict)
print('acc: ', acc)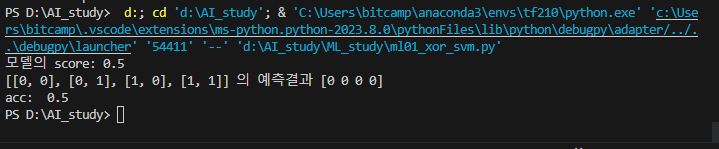
# xor_tf_mlp
import numpy as np
from sklearn.linear_model import Perceptron
from sklearn.svm import SVC, SVR ,LinearSVC, LinearSVR
from sklearn.metrics import accuracy_score
from keras.models import Sequential
from keras.layers import Dense
#1. 데이터
x_data = [[0,0], [0,1], [1,0], [1,1]]
y_data = [0, 1, 1, 0]
#[실습] MLP 구성하여 acc=1.0 만들기
#2. 모델
model = Sequential()
model.add(Dense(32, input_dim=2)) #MLP(Multi layer perceptron)
model.add(Dense(64, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
#3. 컴파일, 훈련
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics='acc')
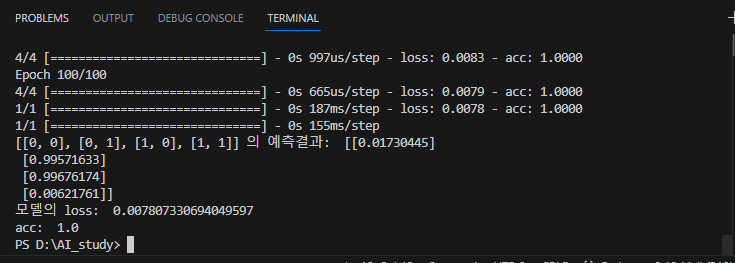
model.fit(x_data,y_data, batch_size=1, epochs=100)
#4 평가,예측
loss,acc = model.evaluate(x_data, y_data)
y_predict = model.predict(x_data)
print(x_data, '의 예측결과: ' , y_predict)
print('모델의 loss: ', loss)
print('acc: ', acc)
#svm_iris
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
#1 데이터
datasets= load_iris()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
print(x.shape, y.shape)
print('y의 label값: ', np.unique(y)) #라벨 값 출력
#2 모델
model =SVC()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과acc:', result)
#svr cali
import numpy as np
from sklearn.svm import LinearSVR, SVR
from sklearn.metrics import accuracy_score
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
#1 데이터
datasets= fetch_california_housing()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
print(x.shape, y.shape)
print('y의 label값: ', np.unique(y)) #라벨 값 출력
#2 모델
model =LinearSVR()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과acc:', result)
#LinearSVR-결과acc:
#SVR- 결과acc: -0.1158887843196934
#scaler_ cali
import numpy as np
from sklearn.svm import LinearSVR, SVR
from sklearn.metrics import accuracy_score
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler,MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77)
#1 데이터
datasets= fetch_california_housing()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
scaler=RobustScaler()
scaler.fit(x_train)
x_train= scaler.transform(x_train)
x_test= scaler.transform(x_test)
#2 모델
model =SVR()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과r2:', result)
#MinMaxScaler 결과r2: 0.6745809218230632
#MaxAbsScaler 결과r2: 0.5901604818199736
#StandardScaler 결과r2: 0.7501108272937165
#RobustScaler 결과r2: 0.6873119065345796#scaler_wine
import numpy as np
from sklearn.svm import LinearSVR, SVR
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler,MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77)
#1 데이터
datasets= load_wine()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
scaler=MaxAbsScaler()
scaler.fit(x_train)
x_train= scaler.transform(x_train)
x_test= scaler.transform(x_test)
#2 모델
model =SVR()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과r2:', result)
#MinMaxScaler 결과r2: 0.92679348255819
#MaxAbsScaler 결과r2: 0.9341580162676605
#StandardScaler 결과r2: 0.9233854624552519
#RobustScaler 결과r2: 0.9252255285031208#tree_ cali
import numpy as np
from sklearn.svm import LinearSVR, SVR
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import accuracy_score
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler,MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77)
#1 데이터
datasets= fetch_california_housing()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
scaler=StandardScaler()
scaler.fit(x_train)
x_train= scaler.transform(x_train)
x_test= scaler.transform(x_test)
#2 모델
model =DecisionTreeRegressor()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과r2:', result)
#MinMaxScaler 결과r2: 0.6745809218230632
#MaxAbsScaler 결과r2: 0.5901604818199736
#StandardScaler 결과r2: 0.7501108272937165
#RobustScaler 결과r2: 0.6873119065345796
#StandardScaler / DecisionTreeRegressor 결과r2: 0.6244514753461712#tree_wine
import numpy as np
from sklearn.svm import LinearSVR, SVR
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, StandardScaler,MaxAbsScaler, RobustScaler
import tensorflow as tf
tf.random.set_seed(77)
#1 데이터
datasets= load_wine()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
scaler=MinMaxScaler()
scaler.fit(x_train)
x_train= scaler.transform(x_train)
x_test= scaler.transform(x_test)
#2 모델
model =DecisionTreeClassifier()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과r2:', result)
#MinMaxScaler 결과r2: 0.92679348255819
#MaxAbsScaler 결과r2: 0.9341580162676605
#StandardScaler 결과r2: 0.9233854624552519
#RobustScaler 결과r2: 0.9252255285031208
#DecisionTreeClassifier 0.8148148148148148# ensemble_iris
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import tensorflow as tf
#1 데이터
datasets= load_iris()
x= datasets['data']
y= datasets['target']
x_train, x_test, y_train, y_test = train_test_split(
x,y,train_size=0.7, random_state=100, shuffle= True
)
print(x.shape, y.shape)
print('y의 label값: ', np.unique(y)) #라벨 값 출력
#2 모델
model =RandomForestRegressor()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
result = model.score(x_test,y_test)
print('결과acc:', result)
# estimatator
import numpy as np
from sklearn.datasets import load_wine
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
from sklearn.utils import all_estimators
from sklearn.preprocessing import MinMaxScaler
#1 데이터
datasets =load_wine()
x=datasets.data
y=datasets.target
x_train,x_test,y_train, y_test= train_test_split(
x,y,train_size=0.7, random_state=42, shuffle=True
)
scaler= MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_test =scaler.transform(x_test)
#2 모델구성
allAllgorithms = all_estimators(type_filter='regressor')
print(len(allAllgorithms)) #55개
#3 출력(평가,예측)
for (name, allAllgorithm) in allAllgorithms:
try:
model= allAllgorithm()
model.fit(x_train,y_train)
y_predict= model.predict(x_test)
r2= r2_score(y_test,y_predict)
print(name,"의 정답률: ",r2)
except:
print(name,"안나온놈")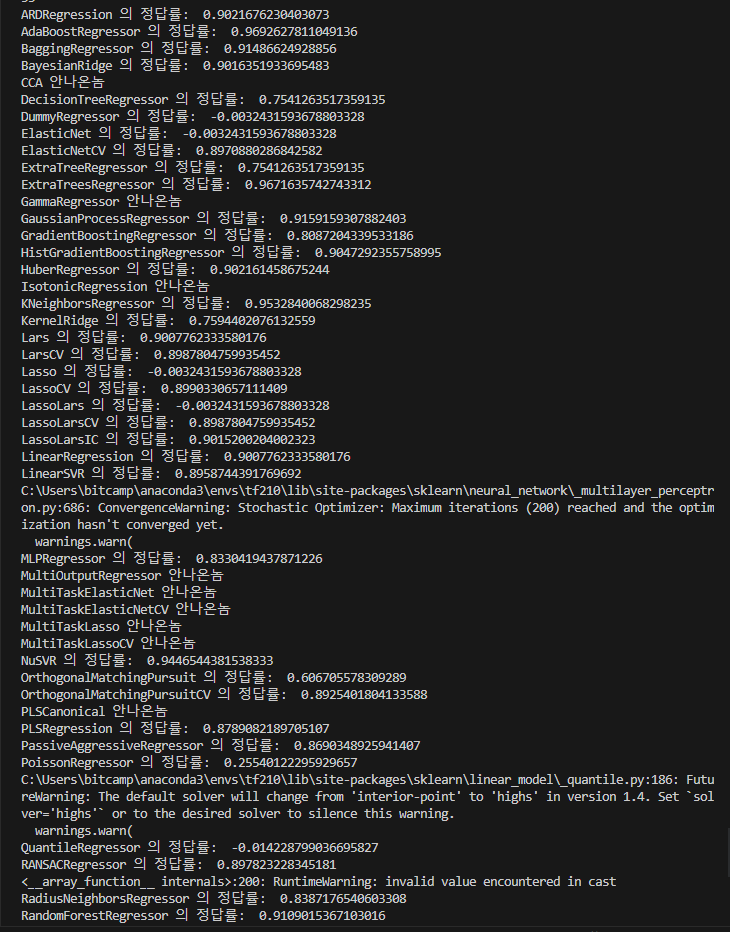
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, KFold, cross_val_score,cross_val_predict
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
tf.random.set_seed(77)
#1 데이터
datasets= load_breast_cancer()
x= datasets['data']
y= datasets['target']
x_train,x_test,y_train, y_test= train_test_split(
x,y,train_size=0.8, shuffle=True, random_state=42
)
#kfold
n_splits=5
random_state=42
kfold= KFold(n_splits=n_splits, shuffle=True, random_state=random_state)
#scaler 적용
scaler= MinMaxScaler()
scaler.fit(x_train)
x_train= scaler.transform(x_train)
x_test=scaler.transform(x_test)
#2 모델
model =RandomForestRegressor()
#3 훈련
model.fit(x_train,y_train)
#4 평가 예측
score = cross_val_score(model, x_train,y_train, cv=kfold)
#print('cv acc:', score)
y_predict = cross_val_predict (model,x_test,y_test,cv=kfold)
#print('cv pred: ', y_predict)
y_predict = np.round(y_predict).astype(int)
acc=accuracy_score(y_test, y_predict)
print('cv pred acc: ', acc)
#cs= cross validatin
#cv pred acc: 0.9666666666666667# feature_importance_cancer
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, KFold, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score, accuracy_score
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = load_breast_cancer()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 5
random_state=42
kfold = StratifiedKFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
#2. 모델
model = RandomForestClassifier()
#model=DecisionTreeClassifier()
#3.훈련
model.fit(x_train, y_train)
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
acc = accuracy_score(y_test, y_predict)
print('cv RandomForestClassifier iris pred acc : ', acc)
#[0.91666667 0.95833333 0.91666667 0.83333333 1. ]
# cv RandomForestClassifier iris pred acc : 0.9666666666666667
# [0.95833333 0.95833333 0.875 0.95833333 0.91666667]
# cv RandomForestClassifier iris pred acc : 0.9666666666666667
####feature importaces
print(model, ":", model.feature_importances_)
import matplotlib.pyplot as plt
n_features = datasets.data.shape[1]
plt.barh(range(n_features), model.feature_importances_,align='center')
plt.yticks(np.arange(n_features), datasets.feature_names)
plt.title('cancer Feature Importances')
plt.ylabel('Feature')
plt.xlabel('importances')
plt.ylim(-1, n_features)
plt.show()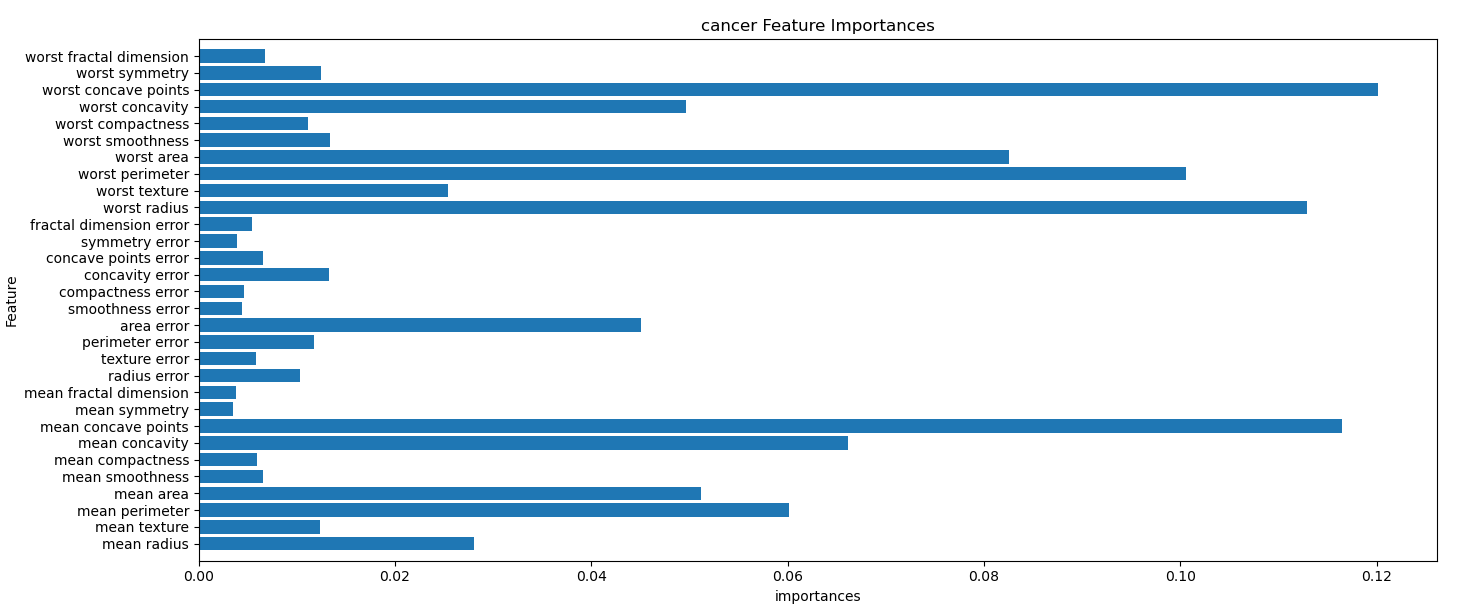
#stratiedkfold
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from sklearn.svm import SVC, LinearSVC
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_val_predict
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
tf.random.set_seed(77)
#1 데이터
datasets= load_iris()
x= datasets['data']
y= datasets['target']
#kfold
kfold= StratifiedKFold(n_splits=11, shuffle=True, random_state=42)
#scaler 적용
scaler= MinMaxScaler()
scaler.fit(x)
x_train= scaler.transform(x)
#2 모델
model =RandomForestRegressor()
#3 훈련
model.fit(x,y)
#4 평가 예측
result = model.score(x,y)
print('결과acc:', result)
#과acc: 0.991458
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
#drop_features
x = np.delete(x, 0, axis=1)
print(x.shape)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 11
random_state=42
kfold = KFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
#2. 모델
model = RandomForestRegressor()
#model=DecisionTreeRegressor()
#3.훈련
model.fit(x_train, y_train)
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
r2 = r2_score(y_test, y_predict)
print('cv RandomForestClassifier iris pred acc : ', r2)
#[0.91666667 0.95833333 0.91666667 0.83333333 1. ]
# cv RandomForestClassifier iris pred acc : 0.9666666666666667
# [0.95833333 0.95833333 0.875 0.95833333 0.91666667]
# cv RandomForestClassifier iris pred acc : 0.9666666666666667
####feature importaces
'''
print(model, ":", model.feature_importances_)
import matplotlib.pyplot as plt
n_features = datasets.data.shape[1]
plt.barh(range(n_features), model.feature_importances_,align='center')
plt.yticks(np.arange(n_features), datasets.feature_names)
plt.title('cali Feature Importances')
plt.ylabel('Feature')
plt.xlabel('importances')
plt.ylim(-1, n_features)
plt.show()
'''import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 5
random_state=42
kfold = KFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
#2. 모델
#model = RandomForestRegressor()
#model=DecisionTreeRegressor()
#from xgboost import XGBRegressor
#model = XGBRegressor()
from catboost import CatBoostRegressor
model= CatBoostRegressor()
#3.훈련
model.fit(x_train, y_train)
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
r2 = r2_score(y_test, y_predict)
print(' catboost pred acc : ', r2)
#XGBRegressors pred acc : 0.7225168753044886
#LGBMRegressor pred acc : 0.7344261735584878
# catboost pred acc : 0.7621118685863372
#catboost 성능이 젤 좋다#LGBRegressor
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 5
random_state=42
kfold = KFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
#2. 모델
#model = RandomForestRegressor()
#model=DecisionTreeRegressor()
#from xgboost import XGBRegressor
#model = XGBRegressor()
from lightgbm import LGBMRegressor
model= LGBMRegressor()
#3.훈련
model.fit(x_train, y_train)
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
r2 = r2_score(y_test, y_predict)
print(' LGBMRegressor pred acc : ', r2)
#XGBRegressors pred acc : 0.7225168753044886
#LGBMRegressor pred acc : 0.7344261735584878#XGB_cali
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 5
random_state=42
kfold = KFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
#2. 모델
#model = RandomForestRegressor()
#model=DecisionTreeRegressor()
#from xgboost import XGBRegressor
#model = XGBRegressor()
from lightgbm import LGBMRegressor
model= LGBMRegressor()
#3.훈련
model.fit(x_train, y_train)
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
r2 = r2_score(y_test, y_predict)
print(' LGBMRegressor pred acc : ', r2)
#XGBRegressors pred acc : 0.7225168753044886