● 그리드서치 (GridSearchCV)
- 하이퍼파라미터 튜닝 : 임의의 값들을 넣어 더 나은 결과를 찾는 방식 → 수정 및 재시도하는 단순 작업의 반복
- 그리드 서치 : 수백 가지 하이퍼파라미터값을 한번에 적용 가능
- 그리드 서치의 원리 : 입력할 하이퍼파라미터 후보들 을 입력한 후, 각 조합에 대해 모두 모델링해보고 최 적의 결과가 나오는 하이퍼파라미터 조합을 확인
ex) max_depth = [3, 5, 10]
Learning_rate = [0.01, 0.05, 0.1]

● XGBoost 모델의 parmeters
- 'n_estimators': [100,200,300,400,500,1000]} #default 100 / 1~inf(무한대) / 정수
- 'learning_rate' : [0.1, 0.2, 0.3, 0.5, 1, 0.01, 0.001] #default 0.3/ 0~1 / learning_rate는 eta라고 해도 적용됨
- 'max_depth' : [None, 2,3,4,5,6,7,8,9,10] #default 3/ 0~inf(무한대) / 정수 => 소수점은 정수로 변환하여 적용해야 함
- 'gamma': [0,1,2,3,4,5,7,10,100] #default 0 / 0~inf
- 'min_child_weight': [0,0.01,0.01,0.1,0.5,1,5,10,100] #default 1 / 0~inf
- 'subsample' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
- 'colsample_bytree' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
- 'colsample_bylevel' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
- 'colsample_bynode' : [0,0.1,0.2,0.3,0.5,0.7,1] #default 1 / 0~1
- 'reg_alpha' : [0, 0.1,0.01,0.001,1,2,10] #default 0 / 0~inf / L1 절대값 가중치 규제 / 그냥 alpha도 적용됨
- 'reg_lambda' : [0, 0.1,0.01,0.001,1,2,10] #default 1 / 0~inf / L2 제곱 가중치 규제 / 그냥 lambda도 적용됨
- XGBoost 모델의 parmeters
참조 공식문서 https://xgboost.readthedocs.io/en/stable/parameter.html
● LightGBM모델의 parmeters
- num_leaves : 하나의 트리가 가질 수 있는 최대 리프 개수
- min_data_in_leaf : 오버피팅을 방지할 수 있는 파라미터, 큰 데이터셋에서는 100이나 1000 정도로 설정
- feature_fraction : 트리를 학습할 때마다 선택하는 feature의 비율
- n_estimators : 결정 트리 개수 learning_rate : 학습률
- reg_lambda : L2 규제 reg_alpha : L1규제 max_depth : 트리 개수 제한
- LightGBM 모델의 parmeters
참조 공식문서 https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
● Catboost모델의 parmeters
- learning_rate: 학습률 depth: 각 트리의 최대 깊이로 과적합을 제어
- l2_leaf_reg: L2 정규화(regularization) 강도로, 과적합을 제어
- colsample_bylevel: 각 트리 레벨에서의 피처 샘플링 비율
- n_estimators: 생성할 트리의 개수
- subsample: 각 트리를 학습할 때 사용할 샘플링 비율
- border_count: 수치형 특성 처리 방법
- ctr_border_count: 범주형 특성 처리 방법
-Catboost 모델의 parmeters
참조 공식문서 https://catboost.ai/en/docs/concepts/python-reference_catboost_grid_search
● 아웃라이어 (Outliers)

- IQR은 사분위 값의 편차를 이용하여 이상치를 걸러내는 방법
- 전체 데이터를 정렬하여 이를 4등분하여 Q1(25%), Q2(50%), Q3(75%), Q4(100%) 중 IQR는 Q3 - Q1 가 됨
● 배깅 (Bagging)
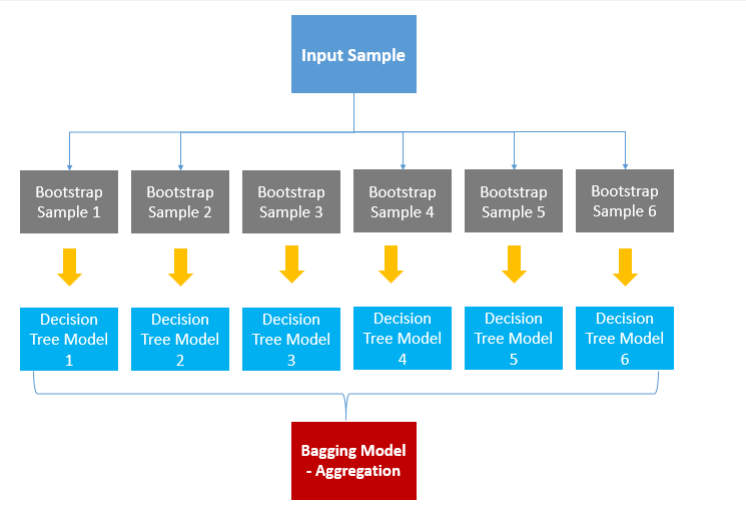
- Bagging은 Bootstrap Aggregation의 약자
- 배깅은 샘플을 여러 번 뽑아 (Bootstrap) 각 모델을 학습시켜 결과물을 집계 (Aggregration) 하는 방법
- 즉, 데이터로부터 부트스트랩 한 데 이터로 모델을 학습시키고 학습된 모델의 결과를 집계하여 최종 결과 값을 도출
#2. 모델
from sklearn.ensemble import BaggingRegressor
from xgboost import XGBRegressor
model = BaggingRegressor(XGBRegressor(),
n_estimators=100,
n_jobs=-1,
random_state=72)
● 보팅 (Voting)

- Voting은 일반적으로 서로 다른 알고리즘 을 가진 분류기를 결합하는 것 (참고 : 배깅 의 경우 각각의 분류기가 모두 같은 유형의 알고리즘을 기반으로 함)
- 하드 보팅: 각 분류기의 예측 결과를 단순 히 다수결(majority voting)로 결정
- 소프트 보팅: 각 분류기의 예측 확률을 평 균하여 예측을 수행
#2. 모델
lr = LogisticRegression()
knn = KNeighborsClassifier(n_neighbors=8)
rfc = RandomForestClassifier()
xgb = XGBClassifier()
model = VotingClassifier(
estimators=[('LR', lr), ('KNN', knn), ('RFC', rfc), ('XGB', xgb)],
voting='soft',
n_jobs=-1)
● 실습 코드
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 5
random_state=42
kfold = KFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
#2. 모델
#model = RandomForestRegressor()
#model=DecisionTreeRegressor()
#from xgboost import XGBRegressor
#model = XGBRegressor()
from lightgbm import LGBMRegressor
model= LGBMRegressor()
#3.훈련
model.fit(x_train, y_train)
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
r2 = r2_score(y_test, y_predict)
print(' LGBMRegressor pred acc : ', r2)
#XGBRegressors pred acc : 0.7225168753044886
#LGBMRegressor pred acc : 0.7344261735584878import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, KFold, StratifiedKFold
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import all_estimators
from sklearn.metrics import r2_score, accuracy_score
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
import warnings
warnings.filterwarnings('ignore')
#1.데이터
datasets = load_iris()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.8, shuffle=True, random_state=42 # valdiation data포함
)
#kfold
n_splits = 5
random_state=42
kfold = StratifiedKFold(n_splits=n_splits,
shuffle=True,
random_state=random_state)
#scaler 적용
scaler = MinMaxScaler()
scaler.fit(x_train)
x = scaler.transform(x)
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# x_test = scaler.transform(x_test)
param = [
{'n_estimators' : [100, 200], 'max_depth' : [6,8,10,12], 'n_jobs' : [-1, 2, 4]},
{'max_depth' : [6,8,10,12], 'min_samples_leaf' : [2,3,5,10]}
]
#2. 모델
from sklearn.model_selection import GridSearchCV
model = RandomForestClassifier(max_depth=6, n_estimators=100, n_jobs=-1)
rf_model= RandomForestClassifier()
#3.훈련
import time
start_time = time.time()
model.fit(x_train, y_train)
end_time = time.time() - start_time
print('걸린 시간 : ', end_time,'초')
print('최적의 파라미터 : ', model.best_params_)
print('최적의 매개변수 : ', model.best_estimator_)
print('best_score : ', model.best_score_)
print('model_score : ', model.score(x_test, y_test))
# 최적의 파라미터 : {'max_depth': 6, 'min_samples_leaf': 3}
# 최적의 매개변수 : RandomForestClassifier(max_depth=6, min_samples_leaf=3)
# best_score : 0.95
# model_score : 1.0
# 걸린 시간 : 6.33348274230957
#4. 결과
score = cross_val_score(model,
x_train, y_train,
cv=kfold) # crossvalidation
print(score)
y_predict = cross_val_predict(model,
x_test, y_test,
cv=kfold)
y_predict = np.round(y_predict).astype(int)
# print('cv predict : ', y_predict)
acc = accuracy_score(y_test, y_predict)
print('cv RandomForestClassifier iris pred acc : ', acc)
#[0.91666667 0.95833333 0.91666667 0.83333333 1. ]
# cv RandomForestClassifier iris pred acc : 0.9666666666666667
# [0.95833333 0.95833333 0.875 0.95833333 0.91666667]
# cv RandomForestClassifier iris pred acc : 0.9666666666666667import numpy as np
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.datasets import fetch_california_housing
import time
from sklearn.preprocessing import MinMaxScaler
#데이터
datasets = fetch_california_housing()
x=datasets.data
y=datasets.target
x_train,x_test,y_train,y_test = train_test_split(
x,y,test_size=0.2, shuffle=True, random_state=42
)
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.fit_transform(x_test)
n_splits=5
kfold= KFold(n_splits=n_splits,
shuffle=True,
random_state=42)
param = {
'n_estimators': [100],
'random_state': [42,62,72],
'max_features': [3,4,7]
}
bagging= BaggingRegressor(DecisionTreeRegressor(),
n_estimators=100,
n_jobs=-1,
random_state=42)
model= GridSearchCV(bagging,param,cv=kfold,refit=True, n_jobs=-1)
start_time = time.time()
bagging.fit(x_train, y_train)
end_time = time.time() -start_time
result= bagging.score(x_test, y_test)
print('최적의 매개변수: ', model.best_estimator_)
print('최적의 파라미터:', model.best_params_)
print('걸린시간: ', end_time, '초')
print('bagging:' ,result)import numpy as np
from sklearn.model_selection import train_test_split, KFold
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import VotingRegressor
from sklearn.metrics import r2_score
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from catboost import CatBoostRegressor
#1. 데이터
datasets = fetch_california_housing()
x = datasets.data
y = datasets.target
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size=0.2, shuffle=True, random_state=42
)
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# [실습] 4시까지 성능향상시키기!!! gridSearchCV를 통한 하이퍼파라미터 적용!!!
#2. 모델
xgb = XGBRegressor()
lgbm = LGBMRegressor()
cat = CatBoostRegressor()
model = VotingRegressor(
estimators=[('xgb', xgb), ('lgbm', lgbm), ('cat', cat)],
n_jobs=-1
)
#3. 훈련
model.fit(x_train, y_train)
#4. 평가, 예측
# y_predict = model.predict(x_test)
# score = accuracy_score(y_test, y_predict)
# print('보팅 결과 : ', score)
regressors = [cat, xgb, lgbm]
for model in regressors:
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
score = r2_score(y_test, y_predict)
class_names = model.__class__.__name__
print('{0} 정확도 : {1: .4f}'.format(class_names, score))
# XGBRegressor 정확도 : 0.7551
# LGBMRegressor 정확도 : 0.8365
# gamma = 3, learning_rat = 0.01,
# max_depth =3, min_child_weight = 0.01,
# n_estimators = 100,
# subsample = 0.1
# CatBoostRegressor 정확도 : 0.8492
# XGBRegressor 정확도 : 0.8287
# LGBMRegressor 정확도 : 0.8365import numpy as np
oliers = np.array([-50, -10, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 50])
oliers = oliers.reshape(-1,1)
print(oliers.shape)
from sklearn.covariance import EllipticEnvelope
outlers = EllipticEnvelope(contamination=.1)
outlers.fit(oliers)
result=outlers.predict(outlers)
print(result)
print(result.shape)import numpy as np
import pandas as pd
data= pd.DataFrame([[2,np.nan,6,8,10],
[2,4,np.nan,8,np.nan],
[2,4,6,8,10],
[np.nan,4,np.nan,8,np.nan]])
# print(data)
# print(data.shape)
data=data.transpose()
data.columns =['x1', 'x2', 'x3', 'x4']
# print(data.isnull())
print(data.isnull().sum())
print(data.info())
#1 결측지 삭제
# print(data.drop(axis=1))
print(data.drop(axis=0))
print(data.shape)
#2 특정값으로 대체
means = data.mean() #평균
median= data.median()# 중간값
data2=data.fillna(means)
print(data2)
data3=data.fillna(median)
print(data3)
# from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import SimpleImputer
imputer = SimpleImputer()
imputer = SimpleImputer(strategy='constant', fill_value=777)
imputer.fit(data)
data2= imputer.transform(data)
print(data2)